Monorepo
We Put Half a Million files in One git Repository, Here's What We Learned
Using a monorepo causes a lot of performance challenges for git. Here's how we solve them at Canva.

At Canva, we made the conscious decision to adopt the monorepo pattern with its benefits and drawbacks. Since the first commit in 2012, the repository has rapidly grown alongside the product in both size and traffic. Over the last 10 years, the code base has grown from a few thousand lines to just under 60 million lines of code in 2022. Every week, hundreds of engineers work across half a million files generating close to a million lines of change (including generated files), tens of thousands of commits, and merging thousands of pull requests.
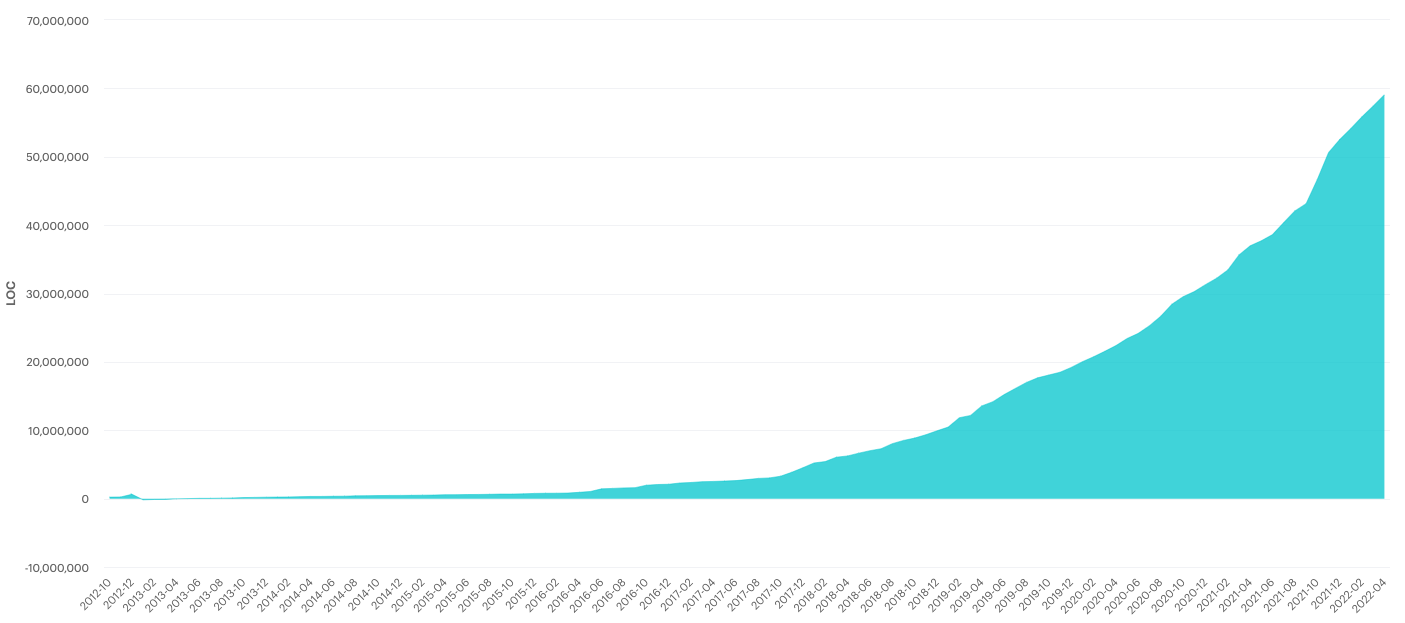
This growth significantly degraded local git performance with commands
like git statustaking longer and longer to run. On a new clone of the
Canva monorepo, git status takes 10 seconds on average while
git fetch can take anywhere from 15 seconds to minutes due to the
number of changes merged by engineers. With the importance of git in
engineers' workflow, running these commands multiple times a day reduces
the total productive time engineers have every day and are long enough
that engineers might context switch, further reducing their
productivity.
Existing solutions
Luckily, we're not the only ones experiencing this problem when working with monorepos. Previous work at Github(opens in a new tab or window), Dropbox(opens in a new tab or window), and recent improvements made to git provides a lot of resources to improve git's performance. Over the years, multiple engineers have made several internal blog posts on how to "make git fast". These culminated in an automated script that engineers are encouraged to use as part of their onboarding process.
Firstly, to reduce the amount of work git needs to do to find changes, we used the fsmonitor(opens in a new tab or window) hook with Watchman so we capture changes as they happen instead of having to scan all files in the repository every time a command is run. We also enabled feature.manyFiles(opens in a new tab or window), which under the hood enables the untracked cache(opens in a new tab or window) to skip directories and files that haven't been modified.
Git also has a built-in command (maintenance(opens in a new tab or window)) to optimize a repository's data, speeding up commands and reducing disk space. This isn't enabled by default, so we register it with a schedule for daily and hourly routines.
What's unique about our monorepo?
Digging deeper into the type of files inside the monorepo, we found that .xlf files made up almost 70% of the total number of files. These .xlf files are generated and contain translated strings for each locale. Even though they live in the monorepo, they are never manually edited by engineers since they're automatically generated when strings are translated. This meant that locally, git is spending resources tracking files that engineers would never change. However, we can't outright delete or ignore these files as they're still needed for our translation system to run smoothly. The next best solution is to tell git to not populate them in our working tree using sparse checkout(opens in a new tab or window), effectively ignoring them locally while still tracking their changes from other sources in the monorepo. Practically we had to include strings for the en-AU locale for other parts of the build system to work, but this is a negligible difference. Though these translations are ignored, our local environments still run with the special en-psaccent pseudo-localized locale by default, so engineers are still conscious of localization requirements.
We did the following experiments with a separate clone of the monorepo with default settings for git and no other optimizations mentioned previously.
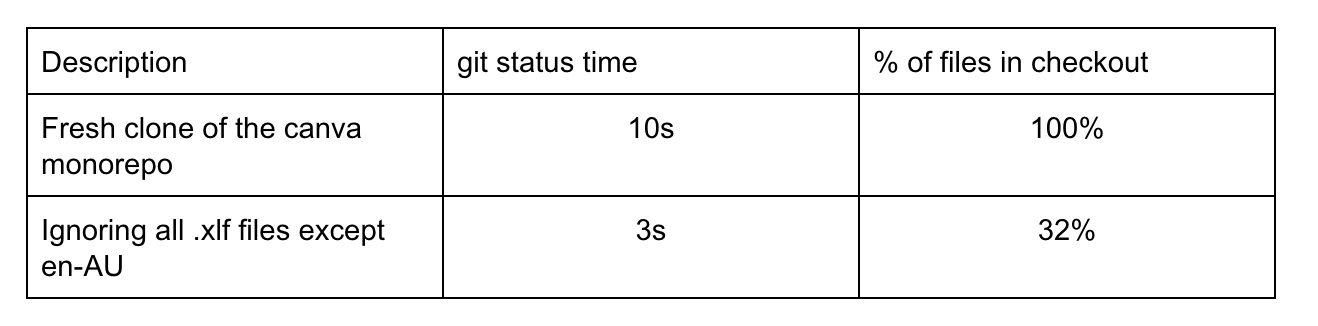
We can take the sparse checkout feature a step further. Our engineers generally work in small teams and interact with an even smaller subset of the monorepo. For example, a frontend engineer working on the editor is unlikely to modify code related to the search or billing server. If an engineer can tell us what they usually work on, we can craft a checkout pattern that includes all the required dependencies to run and test their code locally while keeping the checkout as small as possible.
The Canva monorepo uses Bazel(opens in a new tab or window) as our chosen build system where we define build targets (home page, search server, export button, etc.) and their dependencies. This meant that given a Bazel target, we can accurately determine which files are required to build, run and test it and exclude the rest by querying the Bazel dependency graph. In practice, this required a bit more heuristics as not everything was hooked into the Bazel build graph, and symlinks needed to be resolved, but these were edge cases that could be ironed out. The following table shows a few example configurations and how they impact the checkout.

Backend services tend to modularize better and can run mostly independently while frontend pages less so. This is due to various reasons like typescript configurations, the way our linting is set up, and tools and web pages weren't written with sparse checkout in mind, assuming all files are present at all times. These configurations provide incremental improvements on top of the translation file that each engineer can opt into.
Using sparse checkout is not without drawbacks.
Firstly there are now tracked files not physically populated on disk so they can't be searched through or interacted with. Accidental changes or an erroneous merge conflict might leave these files in a bad state (for example, when two pull requests change the same string to be translated and create a conflict, these files now have to be resolved manually). These are cases that engineers have to be aware of in their workflow.
There's also an overhead applied to every git checkout command to check whether the updated file should be populated or ignored. While this overhead is small with simple patterns like ignoring .xlf files, it becomes significant with more complex ones.
Tying it all together
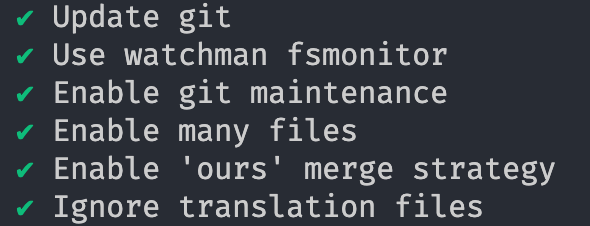
Combining existing git configuration best practices for monorepos and
ignoring translation files, we've reduced git status time to 3s and 2s
with cache. While this is a much better experience for engineers
compared to no changes at all, we still have a long way to go to reduce
this number as the monorepo and number of engineers continue to grow.
Works in progress
These optimizations set a baseline for what is achievable with configurations specifically made for large repositories. But to quantify the impact of git performance on engineers' productivity and further troubleshoot and optimize it, we need to be able to collect telemetry from git operations.
Git already outputs traces through the trace2(opens in a new tab or window) formats that we can capture and send to our central store for analysis. Our team continues to develop an internal tool called Olly to do just this, capturing operation timing, failures and their reasons, tracking new branch creations, and more. This helps us monitor the performance of git across the organization, inform changes we make to git configurations in the future and is the first step in quantifying engineers' development cycle.
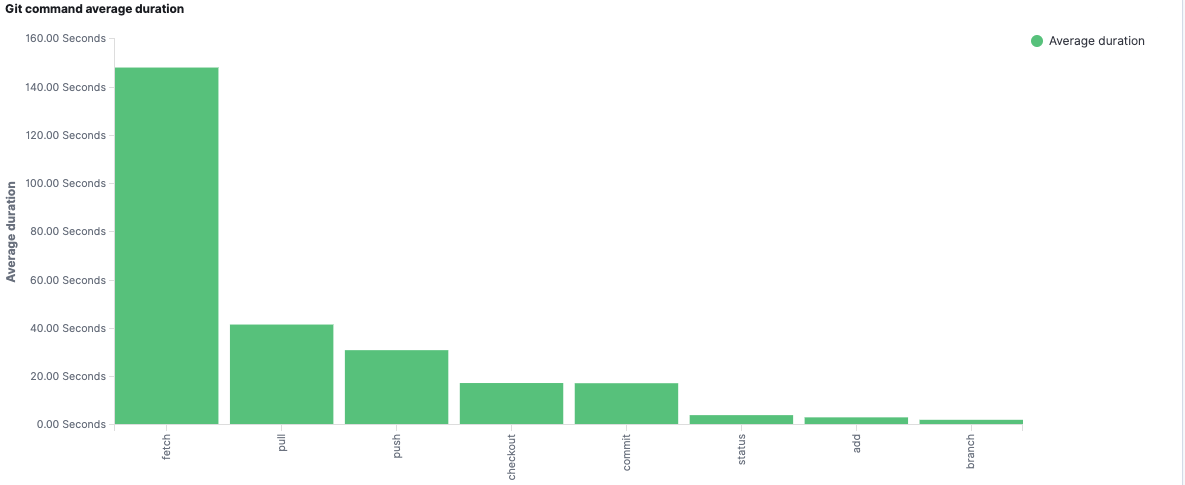
With this telemetry, we can now concretely quantify the impact git performance has on engineers, focus on pain points (git fetch from the above graph), and drill further into each operation.
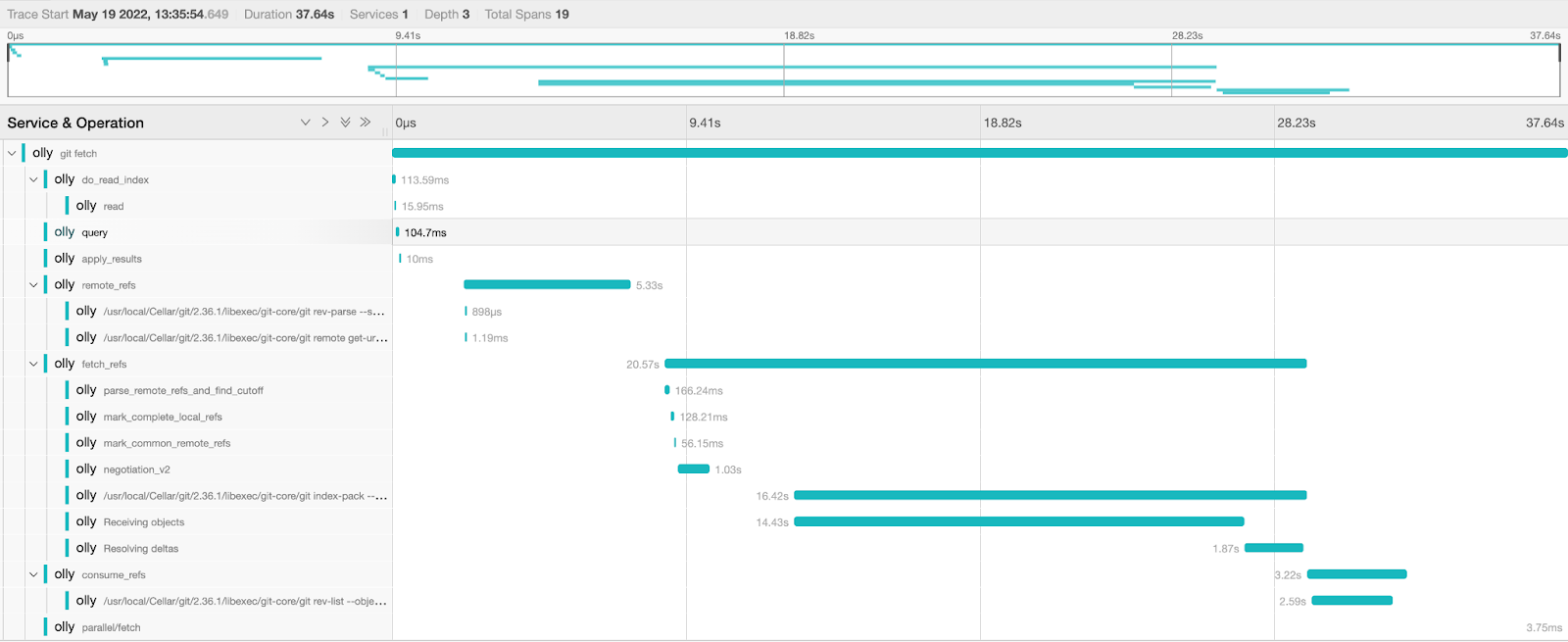
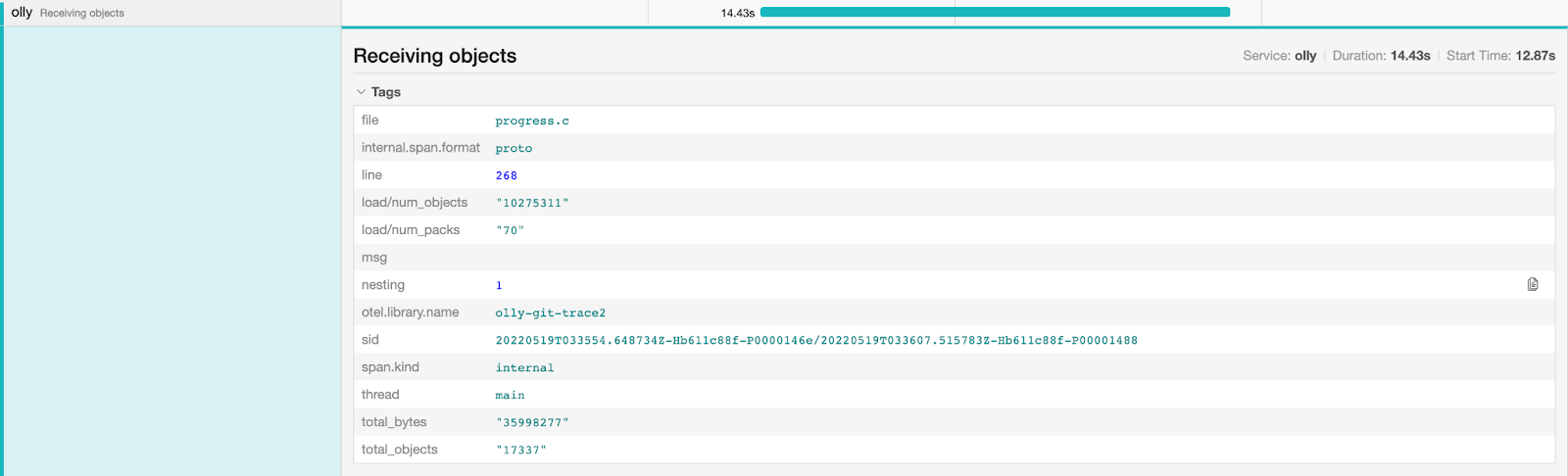
Further, with a recent vulnerability(opens in a new tab or window) in git, we are moving towards providing a known version of git to all engineers with the right configurations by default, ensuring everyone gets the latest security patches and performance improvements.
Acknowledgements
Kudos to other members of the Source Control team — Alex Sadleir(opens in a new tab or window), Wesley Li(opens in a new tab or window), Adam Murray, Matthew Chhoeu — who work on improving git performance at Canva. Special thanks to David Vo(opens in a new tab or window), Uri Baghin and Cameron Moon(opens in a new tab or window) for their expertise and research on git performance.
Interested in optimizing developer experience? Join us!(opens in a new tab or window)


