Search and Relevance
Building a Data-Driven Autocorrection System
This post explains how we built a data-driven system that can perform autocorrection at scale across languages.

Originally published by Ashwanth Fernando(opens in a new tab or window) at product.canva.com(opens in a new tab or window) on July 19, 2019
In the Search team at Canva, we're passionate about providing a fantastic search experience for our users. A challenge we're constantly tackling is how to provide the content that our users are looking for, faster. We try to achieve this in many ways, be it our data-driven search relevance algorithms, our "related searches" pills or our trending searches. These awesome products help users quickly create fabulous designs that they can use to achieve their goals.
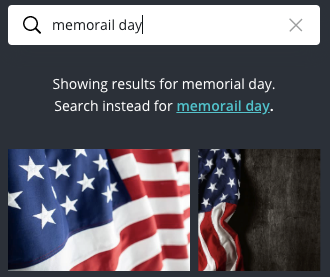
Today we're introducing another feature called Autocorrect that helps users achieve their goals of creating great design. Autocorrection is not new, and is available on other search engines such as Google where if the user makes a typo, Google will correct it or suggest a correction:


Our goal was to build something similar to this where we correct queries behind the scenes if our confidence is high, or else provide a suggestion to the user if not. We also wanted our autocorrection system to be smart and not provide basic rudimentary corrections from a dictionary. For example: When Memorial Day was trending, if users wanted to search for content that resembles memorial day, then autocorrect should be able to correct 'memorail day' to 'memorial day' and perform a search so that our search engine can match documents that are tagged with those keywords.
We also wanted the autocorrection system to learn continually from its mistakes. If users did not like our corrections, then we would demote those corrections to suggestions and would further go ahead to remove them from the suggestion list if they continued to perform poorly.
This post explains how we built a data-driven system that can achieve this feat at scale across languages.
We started off with how to distinguish between a misspelled word and a correctly spelled word. A metric called the Edit/Levenshtein Distance FN_EDIT(wordA, wordB) returns a number that specifies the minimum number of changes required to transform one string to the other. An implementation of the algorithm to compute the Edit Distance from Wikipedia is shown here:
The above algorithm can be optimized to memoize the results of overlapping subproblems created in the recursive calls making the time complexity O(len(wordA)*len(wordB))
For example, the edit distance between 'achievement' and 'achivement' is 1. Assuming we had a dictionary of words, a rudimentary autocorrect system would work if we took the query, split it by tokens and compared each token with all the words in the dictionary, sort them based on increasing order of edit distance and took the first word in that list. This is fairly time consuming (each comparison has a time complexity of O(len(wordA)*len(wordB))) according to the implementation of the algorithm, which would fairly take a while to complete the entire dictionary. We could go one step further and cache the computation which will make subsequent calls for that query faster. One step further again would involve pre-processing all the possible combinations for all words and storing them in a configuration file or database, and having the request do a lookup by each token of the query.
In terms of space complexity, for each word the number of combinations of that word with edit distance 1 is (len * 25). So just for a word like 'achievement', the number of possible typos will be 275 (11 * 25). This is assuming just replacement typos (where a letter has been replaced by another) and not additions or deletions. If we take additions, deletions, case and bigger edit distances into account we will end up with thousands of possible combinations just for one word. In other words, storing each combination is not feasible due to the number of combinations per word.
Given the fact that keyboards are structured in a certain way we had some intuition that we could exploit the proximity of keys and prune a lot of combinations to just the typos that have a high probability of occuring. If we could look at past user queries to extract possible query/replacement pairs, that would be a good first step in identifying those typos that occurred frequently.
The first step was to identify and extract query chains across users, so for example if we had a user that made a series of queries (archery, archer, aarow, arrow) in a session with Canva, we would store those queries. With these queries we were able to strip out chronologically ascending pairs such as (archery, archer), (archery, aarow), (archery, arrow) followed by (archer, aarow) and so on. To learn more about query chains, take a look at this academic paper(opens in a new tab or window).
To achieve a high signal that the latter query in each pair is a valid correction, we also added a conversion metric to each of these queries (i.e. whether the query converted to clicks or revenue). With the conversion metric added to the query we were now able to add a probability score to each query.
P(conversion|query) = number of times the query resulted in a conversion / total number of times the query was made.
We were able to attach this score to each query that was made. Finally we were able to fetch the pairs of interest (a,b) where the edit distance EDIT_DISTANCE(a,b) was greater than or equal to 1 and less than or equal to 3 and the probability score of b was greater than A. The graphic below shows this entire flow for a few events.
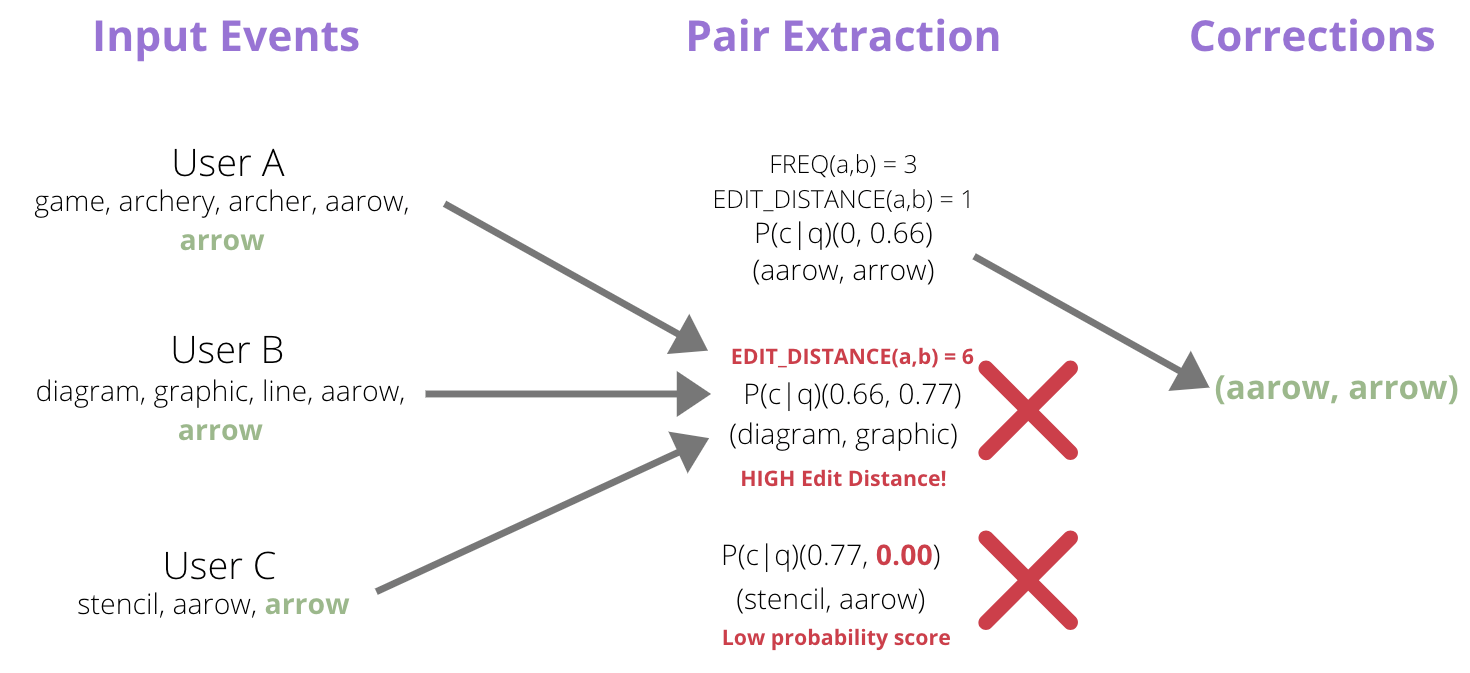
The above example shows the sessions of three users and how we filter a correct autocorrection pair (aarow, arrow) from those events. The pair (diagram, graphic) was rejected because the edit distance was high, (stencil, aarow) was rejected because the probability score of conversion was low for arrow.
When we did this across a week of events, the approach yielded some pretty impressive results. This was a small sample of output for the possible corrections of facebook:
("afcebook", "facebook"), ("faacebook", "facebook"), ("fabook", "facebook"), ("faacebook", "facebook"), ("fabook", "facebook"), ("facaebook","facebook")
To add more signals to the value of our pairs, the frequency of times a pair occurred was also considered to be an important metric. Pairs that occurred only once within the window of a month were dropped out from the final list.
These suggestions were highly relevant, and targeted typos while adding a ton of value for all of our users. We were also able to capture corrections associated with trending events such as 'memorial day' and all the possible typos as a result of it while avoiding wasteful combinations that did not occur and had no chance of typographic errors.
We were able to run the data extraction as described above with an extraction window size of 2 months resulting in close to 32000 corrections for one of our locales.
One thing that we were worried about was the presence of incorrect suggestions such as "cat" -> "cot" — both of these words had an edit distance of 1 and in the time window that we used, "cot" had a higher probability score than "cat". To test the accuracy of our autocorrection a small test percentage of traffic was directed to the autocorrect feature to see the number of times suggestions were surfaced vs. rejections.
The blue timeseries chart shows the number of times autocorrections were surfaced within a given window.

The rejections were barely visible but they are the red lines on the bottom of the graph ( occurring 0.1—1% of the time).
These are good results. However we want the rejections to asymptote towards zero in the long term. To help achieve this, we plan to use the rejection data captured from user events to demote corrections to suggestions instead and if they still perform poorly, remove them from the configuration altogether.
We plan to regularly run our extraction data pipeline for autocorrection which will capture current autocorrection pairs and append them to the existing config. During this time we will also scan for rejections and remove them.
There's still plenty of work ahead for us in building this system but we've made some good first steps. Another side benefit of building an autocorrect system this way is to avoid any sort of human curation for the (query, correction) pairs as the system will create and refine them continuously.
We currently have autocorrection deployed for all users of English speaking locales with plans to expand to other locales soon. Our data extraction currently runs in a jupyter notebook and most of the logic is single threaded thus limiting the size of our window. We are currently planning to run the data extraction job with Apache Spark so that we can extract and compute most of the logic in parallel which will also enable a bigger window of extraction for user generated events. A bigger window of maybe 6 months would result in better autocorrection quality across the range of vocabulary.
As a company one of our values is to "Make complex things simple". A lot of this comes down to removing all the obstacles that get in the way of enabling our highly creative customers to build great designs that help communicate their thoughts. We believe our data-driven autocorrection system for Canva's search helps move the needle in that direction.
Building autocorrect for Canva is the effort resulting from the culmination of engineers and data scientists including Glen Pink(opens in a new tab or window), Will Radford(opens in a new tab or window), Paul Tune(opens in a new tab or window) and myself(opens in a new tab or window).