Engineering
Summarizing Post Incident Reviews with GPT-4
How we use GPT-4 to summarize incident reports.

Canva is an online graphic design platform that provides design tools and access to a vast library of ingredients for its users to create content. We have over 150 million monthly active users with over 17 billion designs across more than 100 languages.
Maintaining a smooth user experience requires tracking and analyzing incidents during Canva's development phases. We record Post Incident Reports (PIRs) in Confluence, paired with short summaries to enhance readability and reporting. Summaries help engineers quickly identify relevant incidents.
Previously, our reliability engineers wrote the incident summaries at the end of incidents. Over time, we noticed that reviewers often needed more context to review the summary quickly and effectively and that the summaries were becoming inconsistent. We now use GPT-4-chat to auto-generate our PIR summaries, improving data quality, ensuring quality summaries, and reducing the workload of our engineers.
The workflow
The following diagram illustrates the workflow we use for transforming a raw PIR into a summary.
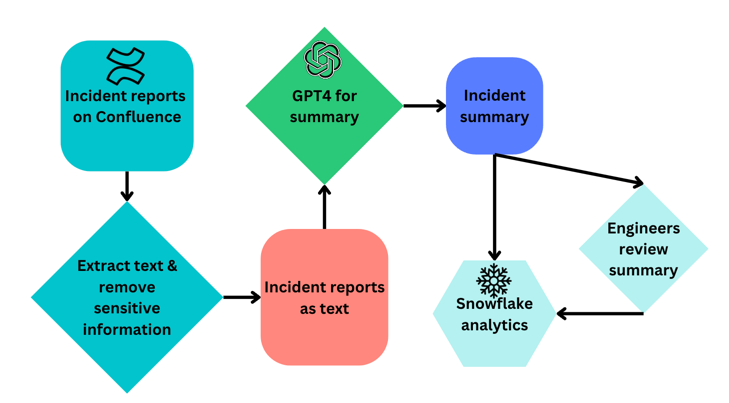
We start by fetching the report from Confluence and parsing the HTML to extract the content of the PIR as raw text. We then remove sensitive data, including links, emails, and Slack channel names, to avoid exposing internal information to public models and ensure blameless summaries. We then send the text version of the report to GPT-4 chat completion(opens in a new tab or window) to generate a summary.
After generating the summary, we archive it in our data warehouse, allowing us to integrate it with additional incident metadata, which we store for comprehensive reporting purposes. We also include the summary on the Jira tickets for the incident, so any manual changes are recorded to the warehouse using Jira webhooks. This allows us to compare the AI-generated and human-modified summaries to monitor the data quality.
Choosing GPT-4-Chat as our LLM
At the time of writing this post, OpenAI's(opens in a new tab or window) models stand as the most competitive options, offering the highest quality in terms of interpretation and understanding instructions. Consequently, we opted to employ GPT models for the summarization tasks. The 3 potential models we explored were:
- GPT fine tune (davinci-002)(opens in a new tab or window)
- GPT completion (gpt-4-32k)(opens in a new tab or window)
- GPT chat (gpt-4-32k)(opens in a new tab or window).
Each service incurs a linear cost per report, the most expensive being GPT-4 at $0.06 per 1K tokens. Given that a single PIR, along with sample PIRs and corresponding summaries that inform the GPT model of the expected response format, can contain up to 10,000 tokens, the maximum estimated cost per summary is a manageable $0.6. Therefore, we selected the most potent model for each service.
Fine-tuning involves training a customized model based on GPT's architecture using input-output pairs we provide. We confine our available training data to existing PIRs and their summaries, amounting to around 1500 examples of varied quality. This quantity is insufficient for cultivating a fine-tuned model capable of discerning the specific details we want to extract from the reports, leading us to discard this option.
Manual comparison of about 40 summaries generated by the fine-tune method against the other two methods showed that both GPT completion and GPT chat outperformed the fine-tuned model, exhibiting the following strengths:
- Accurately determining impact duration from the start and end times, a detail frequently overlooked by the fine-tuned model.
- Effectively correlating various incident phases, such as deducing how resolution methods relate to the causes, whereas the fine-tuned model often isolates different factors.
- Using the capabilities of GPT-4, surpassing the fine-tuned model, which supports up to davinci-002, nearing the proficiency of GPT-3.5 but still missing critical details.
While the completion API(opens in a new tab or window) requires details in a single paragraph, resulting in a more flexible but potentially inconsistent response format, the chat API(opens in a new tab or window) allows system messages to guide the structure of the expected summary elements. Moreover, dividing the PIR and summary into messages labeled as "user" and "assistant"(opens in a new tab or window) improves the GPT chat API's ability to comprehend the intended format, securing more consistent summary quality. Given these advantages, we chose GPT-4-chat as the Large Language Model (LLM) for creating summaries.
Prompts for summary
We use the following prompts to the GPT-4 chat endpoint(opens in a new tab or window). In these prompts, the term PIR-new represents the PIR from which we want to produce a summary. Our prompt structure looks like the following.
"messages": [{ "role": "system", "content": "<summary prompt>" },{ "role": "user", "content": "<PIR1>" },{ "role": "assistant", "content": "<Summary 1>" },{ "role": "user", "content": "<PIR2>" },{ "role": "assistant", "content": "<Summary 2>" },{ "role": "user", "content": "<PIR-new>" }]
The summary prompt looks like the following.
You are an experienced Site Reliability Engineer understand different CS terms and their usage.Goals: Summarising reliability reports in a blameless manner, sentences within summaries should be coherent.Constrains:1. The summary should be in a flexible format, with key components connected to each other.2. Here are some key components desired in the summary if they are present in the original PIR:- Detection Methods: Manual vs Monitoring alert, with some more details- Impacted Groups- Affected Service- Duration- Root Cause- Trigger- Mitigation Method3. Focus on the systemic issues and facts without attributing errors or oversights to individuals.4. Do not introduce new information, only extract and distill the salient points from the report.5. Do not give any suggestion. Just summary.
The following are some insights about our prompt design:
-
We instruct the language model in two main ways. We:
- Emphasize the importance of adhering strictly to the provided details without deviation.
- Direct it to adopt a blameless approach. This aims to make sure the model doesn't blame any individual.
Our tests, especially with made-up PIRs that explicitly blame individuals, prove the model's blameless stance to a certain extent. By setting the temperature to 0 when interfacing with the chat API endpoint, we further make sure the AI's output is devoid of artificially generated content.
-
We guide the desired outcomes by listing key factors at the end of the prompt. This strategy makes sure the resulting summary captures the essential elements we aim for.
-
Instead of defining a response length when making an API request, we request the model in the prompt to target a 600-character limit. Directly limiting the API response can lead to truncated or unfinished outputs. By specifying the desired length in the prompt, we aim for concise responses. While this approach doesn't ensure responses under 600 characters, it helps avoid overly lengthy ones. If a summary exceeds the desired length, we resubmit it to GPT-4 chat for further condensing.
-
We offer two sets of PIR samples along with their summaries. Using multiple examples prevents GPT from rigidly mirroring the structure of a single given summary. Providing two sets strikes a balance, allowing the model to understand our desired response format while encouraging a variety of summary structures.
Results comparison
We document the original summaries produced by GPT-4 and the versions revised by our engineers. After running the project for approximately two months, data indicates that most of the AI-generated PIR summaries remain unaltered by engineers. This underscores the engineers' approval of the AI's output and attests to GPT-4's proficiency in expediting PIR review stages. Moreover, this process yields a large collection of summaries suitable for archiving and reporting.
Conclusion
Implementing GPT-4-chat for summarizing PIRs at Canva has significantly improved the efficiency and consistency of the process. The AI model reduced the operational toil of reliability engineers and produced higher-quality summaries that met the team's approval, with most remaining unaltered. Using GPT-4-chat is cost-effective and capable of understanding and adhering to the specific requirements of the task. This successful application of AI technology demonstrates its potential to enhance operational efficiency and quality in various aspects of business operations.
Acknowledgements
This work would not be possible without the support from Jackson W Cleary(opens in a new tab or window), who shared lots of experience about prompt engineering, Christian Marie(opens in a new tab or window), who was with us in this journey from the very beginning ❤️ and our entire organization.
Inspired by this post? Passionate about AI? Join us(opens in a new tab or window)!