Recommender Systems
Recommender systems: When they fail, who are you gonna call?
How we deal with potential problems when running Canva's recommendation system.

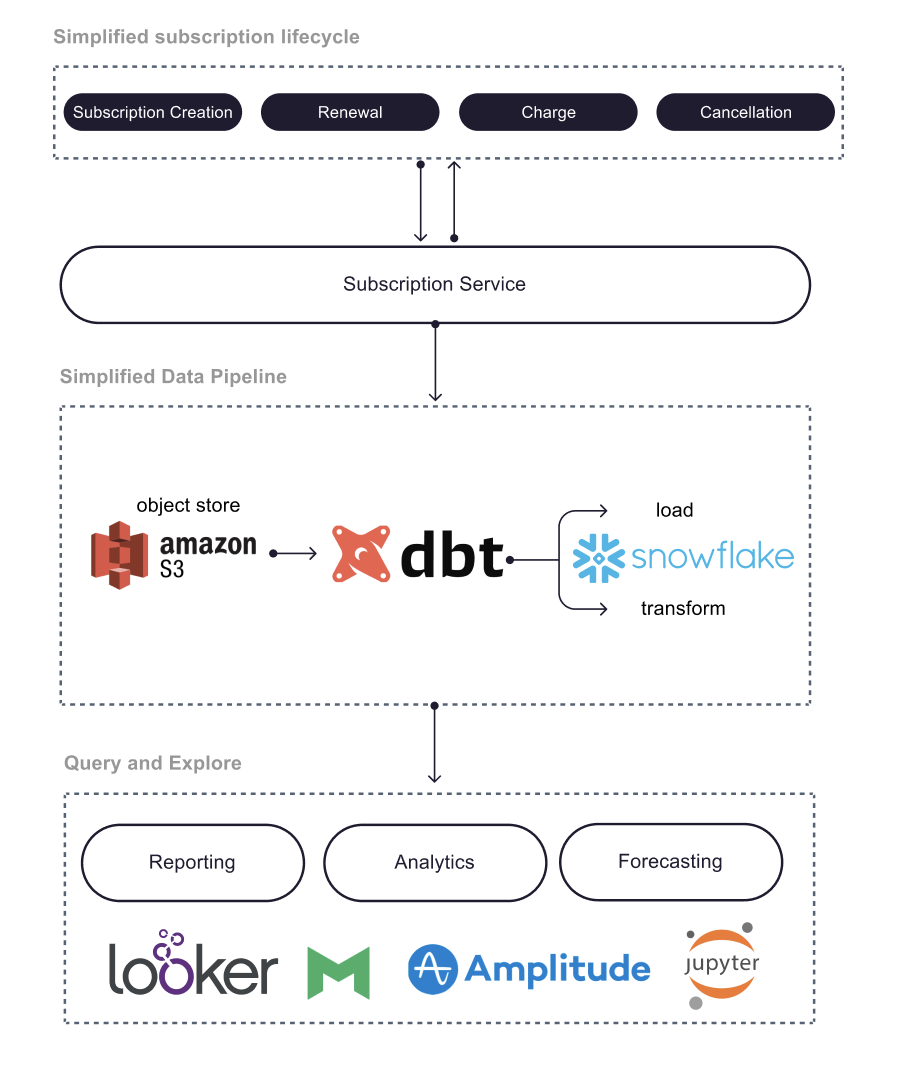
At Canva, we're always working to improve the user experience of our product. We constantly seek to empower everyone to design regardless of their design experience. One way we do this is to make sure everyone gets a personalized experience using recommendations, which get better the more you use Canva!
Personalization for everyone is no small feat. Canva has more than 60 million monthly active users(opens in a new tab or window), each with their own unique personality. To each user, we want to present a fast and efficient personalized experience, which also reacts to their decisions when designing. Any time someone makes a Poster for a Yard Sale, for example, we improve our recommendations to have a better picture of what that person likes and what interests them.
But sometimes, these recommendations can go wrong.
In this post, we detail the ways Canva mitigates some of the operational issues we've encountered when attempting to place our personalization magic across multiple services in our product. This post breaks down the two common failure modes we see when implementing personalization at such a massive scale: unexpected results and failure to respond.
Unexpected results
Unexpected results come in two forms: empty recommendations and irrelevant results. Recommendation models aren't always perfect, and in some circumstances, recommendation models might not always produce the results creators expected. Our models are no exception. Sometimes they might not produce results, while other times they might produce really irrelevant ones. Mitigating the effects of these situations is important for consistent user experience.
Empty recommendations
There are usually two main reasons for empty recommendations (assuming that the model is functioning perfectly in the majority of cases):
- The cold start problem(opens in a new tab or window), which happens with new users who have limited interactions. The model might not be confident enough in the results it provided to give a good personalized recommendation.
- Application logic when the condition isn't suitable to use a recommendation model. For example, there's a model trained to recommend the next template based on your last-used template, and if you haven't used any templates, there could be no next template to recommend for you based on missing application data.
So what do we recommend to users when we have no results?
One approach is to have some understanding of what's popular and engaging for most users. In these cases, the result can be a fallback set of outputs based solely on features we know and can infer from the request. These can include the users' geographical locations, the time of year, language settings, and the devices they are using, to name a few. We showcase this on our templates homepage(opens in a new tab or window), where we personalize all the templates shown to the user, but if we don't get any results, we fall back to broad recommendations, which are locale and platform-specific.
In cases where there's not enough data to provide to the recommendation model, sometimes it's better to give nothing at all that is, if you don't have anything good to say, don't say anything at all. You can see this approach in our Magic Recommendations feature, which is shown to the user when we find recommendations but is hidden from the user if there are no recommendations.
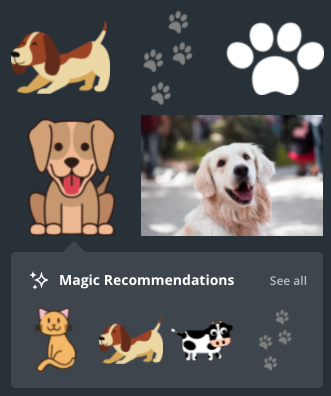
Irrelevant results
What's worse than no results? Results that are just plain irrelevant, not to the user's taste, or random. In many situations, providing users with no recommendations instead of showing recommendations you're not confident in results in a better user experience. Showing users something they're not expecting can be a jarring experience especially when dealing with new or irrelevant content.
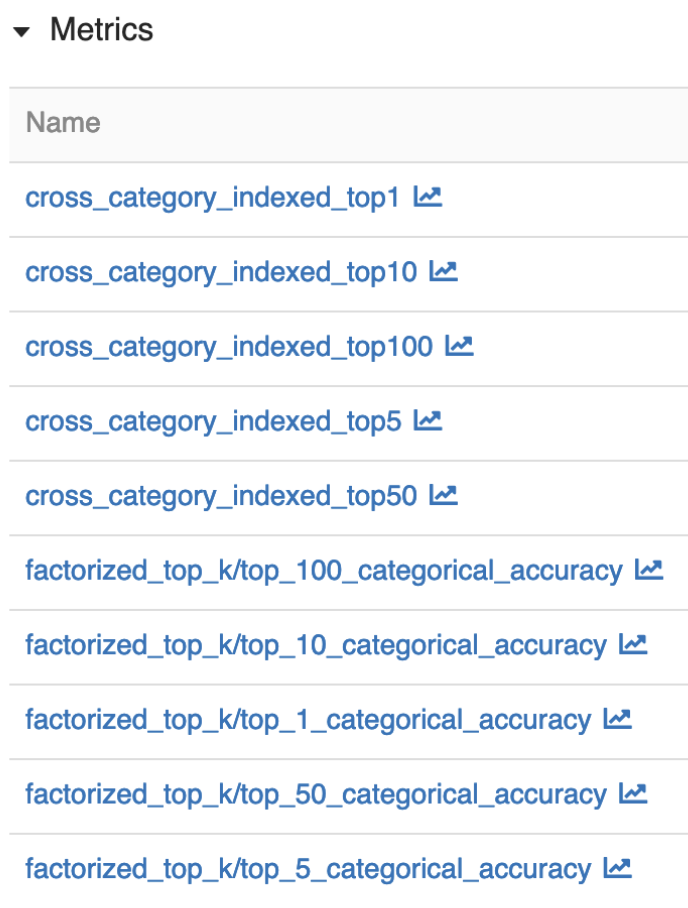
So how do you combat this issue? When building models, make sure you test them with validations sets so that the results from your recommender are relevant. One of the ways you can do this is to use validation sets to measure success across different metrics across different aspects of the model. When relevant model metrics are below a certain threshold, we might block the new deployment of that particular model until we have a better result.
At training time, you can use metrics in many different ways to measure different aspects of the system. Firstly, the performance of the model itself. Is the model accurate enough? Has the model regressed in predictive power? Does the model surface enough of the content? You can test the core model directly against datasets to give strong numerical answers to these questions.
However, it's not just a model that makes up a recommendation system.
There are server layers, data manipulation code, fallback code, etc., that need to work together. For this, it's possible to add tests to check the recommendation server is functioning as a whole. An example of this is to use performance tests to ensure that the server and model can handle high traffic loads.
It's also always helpful to produce model reports that display the recommendations coming from the model as a visual indicator, so you can understand what the result will look like in the product. These reports can help to identify problems that might not be obvious from the numerical metrics. For example, if the recommended templates are identical except for the size, the machine learning metrics might give this result a high score. Each individual recommendation is technically a good recommendation, but as a whole, a row of identical templates is not a good user experience. So visually inspecting the output provides a good way to monitor and debug the recommendations in a visual way.
At inference time, we need to perform other validation steps after receiving content from the recommendation models into the backend. These steps include filtering out duplicates and filtering out malformed results. Malformed results include invalid result IDs or broken metadata when these IDs are converted into actual recommendation objects (the image URL might be malformed, the resulting image might be corrupted, the media is deleted, the result doesn't meet the required criteria, etc.).
Following validation of these results, there could be times where the recommendations are known to be sub-optimal despite being theoretically highly relevant to the user. For example, this could be because we have a restriction to not show Canva Pro(opens in a new tab or window) recommendations (this user is on a free account), or we have a manual curation for this kind of recommendation to satisfy a product initiative. In these cases, it's very important to ensure that product impact through recommendations is measured because it might not always be the right choice.
Failure to respond
Failing to respond can be caused by a multitude of reasons, and mitigating them can be tricky. Recommendation models are only valuable if they can produce recommendations quickly. Unfortunately, some models might take a long time to respond, or models might break in the middle of the night during peak traffic because of load issues. Knowing how to handle these cases is important to maximize the value of those machine learning models.
High latency
It's important to ensure your recommendations are fast and performant so that they can scale during high traffic loads. However, some large deep learning models are not as performant, both in latency and scaling time. Because of that, we use a couple of methods to speed up slow models to ensure the product is responsive and doesn't negatively affect user experience.
Vertical and horizontal scaling. Vertical and horizontal scaling might seem obvious, but knowing when to do vertical versus horizontal scaling requires knowing how model inference works. Horizontal scaling means using more machines to handle the workload, which can help with handling multiple concurrent requests. By contrast, vertical scaling means using larger machines, which can help with reducing the time it takes to process each request. Since the deep learning models are basically lots of parallelizable matrix multiplication operations, they can take advantage of all the cores in the machines. Therefore, the bigger the machine is, the faster it can process requests.

Using a combination of vertical and horizontal scaling is beneficial. We have an auto-scaling policy that horizontally scales our fleet based on the average number of requests for each instance. At the same time, we regularly audit our configuration to make sure the machine type we're using can produce output at an acceptable latency under load.
Caching. Caching is another obvious solution to reduce latency, but knowing how to do it while keeping the recommendation reactive to user interaction is not easy. If you want to have static predictions, you can pre-calculate predictions for all users daily and store them in a database that is quick to query. But what if you want to maintain a dynamic product experience and keep your recommendations reactive to the user's interactions? In Canva, if the user has just used an Instagram template to create an Instagram post, we want our recommendation models to recommend the next design template the user wants to make. We can do that by showing more Instagram templates that are visually or contextually related to what the user last used.
To solve the latency problem, we introduced near-line inference into our service. This means actively updating recommendations in the background and storing them in a caching layer while the user interacts with the system.
An example of this approach at Canva is our template recommendation model. Template recommendations occur whenever a user interacts with a template, for example, when creating a new design from the Canva template page(opens in a new tab or window) or applying a new template from the Canva editor. This gives us time in between these interactions to pre-calculate our predictions and reduce the latency when users request fresh recommendations.
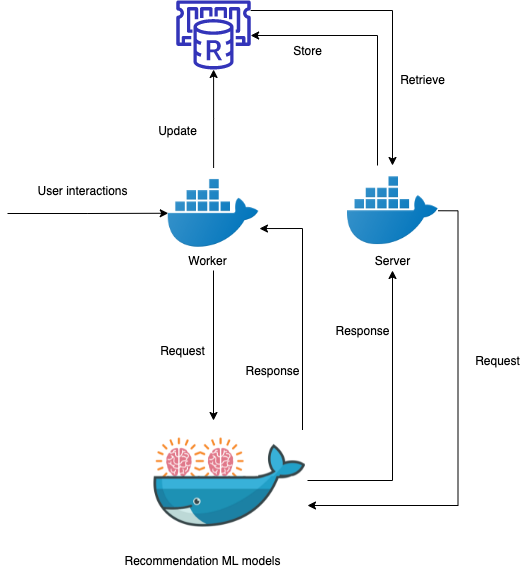
Every time a user interacts with a template, in the background, we call the recommendation models and update the caches for that user with the new recommendations. This way, when they need to load the recommendations, we only need to query from our low latency cache while remaining reactive to user's interactions.
Optimizing the model. It's important to ensure that the people building the models are also responsible for the models' performance in production. This helps to avoid differing ideas or trying to optimize for competing metrics. This, of course, includes making sure the model responds fast enough for user requests.
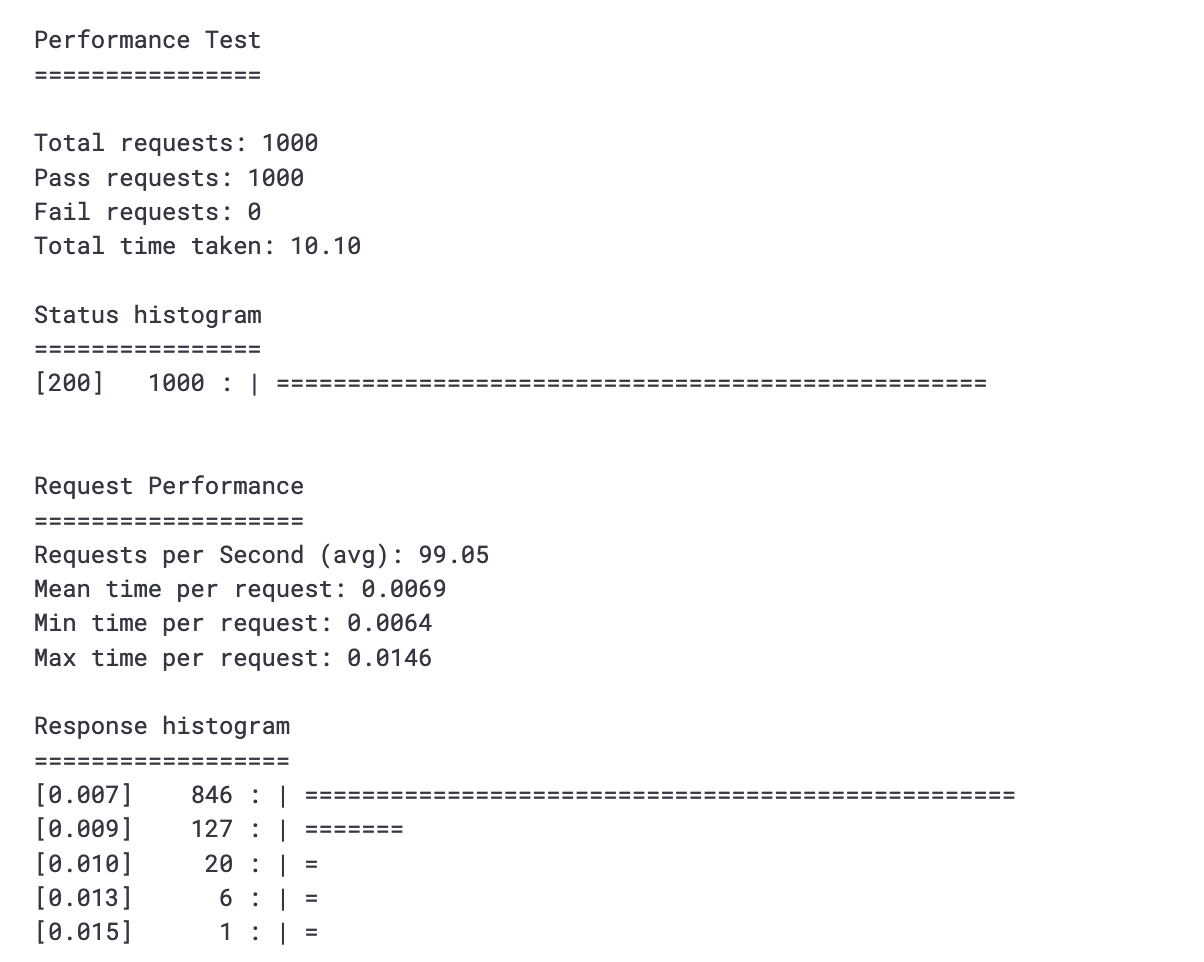
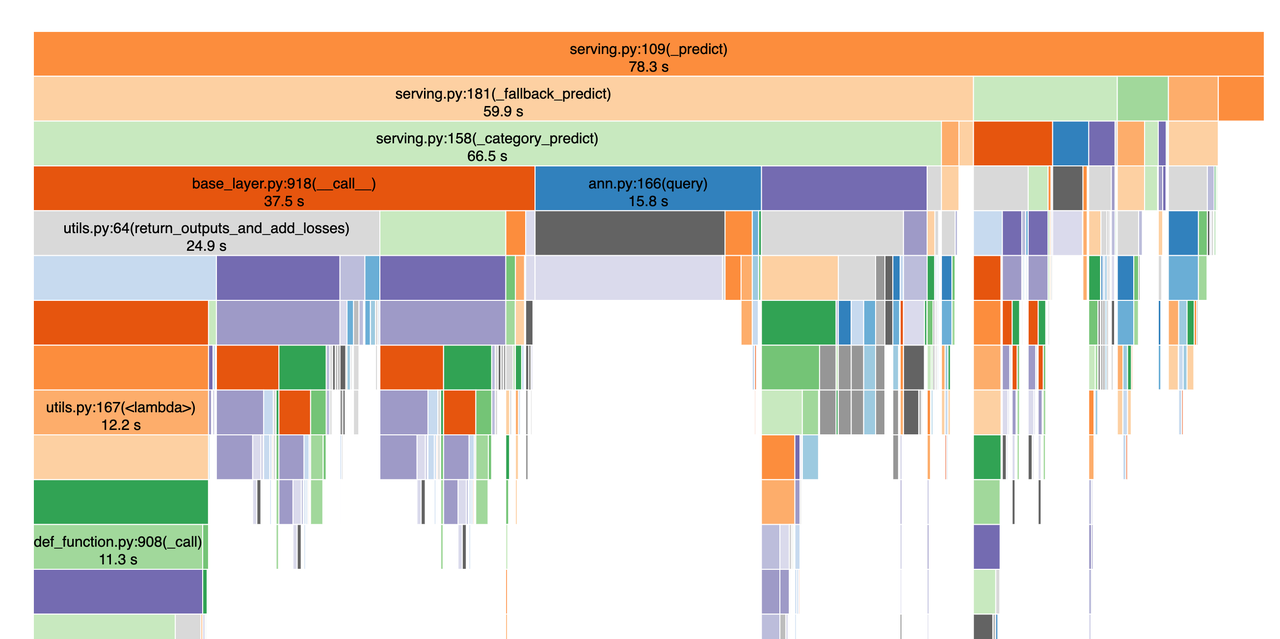
A performance profiling step is very useful here, where we can check the speed of the newly trained models and generate a performance profile of the code. This is useful in the cases where the overall model is not fast enough, we know where to optimize it.
Code red, failure, what do we do?
While in general, the most common failure of machine learning models in production is that they don't produce good enough results because of data drift(opens in a new tab or window), we've also reached horizontal scaling limits multiple times, either because of Canva's fast-growing user base, or a new model that needs larger machines to run on. Since most of our engineers are based in Australia, unfortunately, peak traffic typically happens while our engineers are asleep. And because on-call engineers are the only ones woken for an alert, it's important they can handle situations independently and quickly.
Deploying a new machine learning model is not fast or easy (some of the models we have take around 15 to 20 minutes to scale), a roll forward is generally not an option. Therefore, the two main ways to handle the situation are either a rollback or a switch-off. We generally prefer to roll back whenever possible because we still provide the benefit of the model to our users. However, sometimes we do need to temporarily switch off a particular model and rely on our generic fallback recommendations rather than personalized ones. For example, when the model might be failing to scale because we've reached a scaling limit that needs to be increased by our cloud provider, simply rolling back versions wouldn't reduce the user traffic.
It's important that each model has an independent controller so that switching off any single model doesn't affect other models. Turning these models off can either set the model into a fallback state where it provides generic fallback recommendations for everyone, or it can just return no results for every request. We will turn the model back on after we know it is safe to do so, either by having higher scaling limits or a smaller model.
Only just the beginning
As Canva continues to scale, in both users and content, we're really excited to keep expanding and enhancing our recommendation systems. This means treading new ground and pushing machine learning into new areas of the product, and ensuring that reliability is maintained.
We're always keen to solve new and interesting challenges with our recommenders and to improve the reliability and robustness of our models to provide our users with the best possible Canva experience.
Acknowledgements
Special thanks to Alex Collins(opens in a new tab or window), Rohan Mirchandani(opens in a new tab or window) and Adam Lee-Brown(opens in a new tab or window) for reviewing this post. Huge thanks to Grant Noble(opens in a new tab or window), Sergey Tselovalnikov(opens in a new tab or window) and Paul Tune(opens in a new tab or window) for suggestions in improving the post.
Interested in improving our recommendation systems? Join us!(opens in a new tab or window)