Machine Learning Infrastructure
Supporting GPU-accelerated Machine Learning with Kubernetes and Nix
It ain't what you don't know that gets you into trouble — well, sometimes it is.

Canva(opens in a new tab or window) is an online graphic design platform, providing design tools and access to a vast library of ingredients for its users to create content. Leveraging GPU-accelerated machine learning (ML) within our graphic design platform has allowed us to offer simple but powerful product features to users. We use ML to remove image backgrounds(opens in a new tab or window) and sharpen our core recommendation, searching, and personalization capabilities.
In the middle of 2021, the ML Platform team rebuilt the container base
images we use in our cloud GPU stack FROM scratch, using
Nix(opens in a new tab or window). Nix is many things: a functional package
manager, an operating system (NixOS), and even a language. At Canva we
widely employ the Nix package management tooling, and for this image
rebuilding work Nix's dockerTools.buildImage function was crucial.
When setup on x86_64 Linux, Nix's dockerTools.buildImage function
happily baked and ejected a CUDA-engorged base image. Unfortunately, our
initial rebuilt images were incorrect. To discover why and produce a
subsequent correct deployment, we had to get serious about the following
question.
When an ML platform user submits this program to our cluster,
import torch; print(torch.cuda.get_device_name(0))
… why are we sure the program will find the GPU and print its name, "Tesla T4"?
It's a question that tempts hand-waving, but let's stick to the facts and focus on demystifying the stack that powers our GPU-enhanced ML workflows.
What's in a cloud GPU sandwich?
To run a GPU-accelerated application in our Kubernetes (K8s) compute cluster, we employ a sandwich of components. From bottom to top, the components we need correctly connected together are:
- A host operating system (OS) running in a VM as a Kubernetes node.
- The container runtime — including extensions for GPU interoperability.
- A GPU device 'mapper' (not pictured) — allows individual containers to connect, via an NVIDIA device driver, to the underlying GPU peripheral hardware.
- The Nix 'base' container image, built using
Nix's
dockerTools(opens in a new tab or window) and containing only the essential system files required to run our GPU-accelerated Python applications. - An application container image, bundling in the GPU-enabled Python framework (PyTorch or Tensorflow) and Python application code. This is layered on our Nix 'base' image, adding only application source code and third-party Python package files such as PyTorch or Tensorflow.
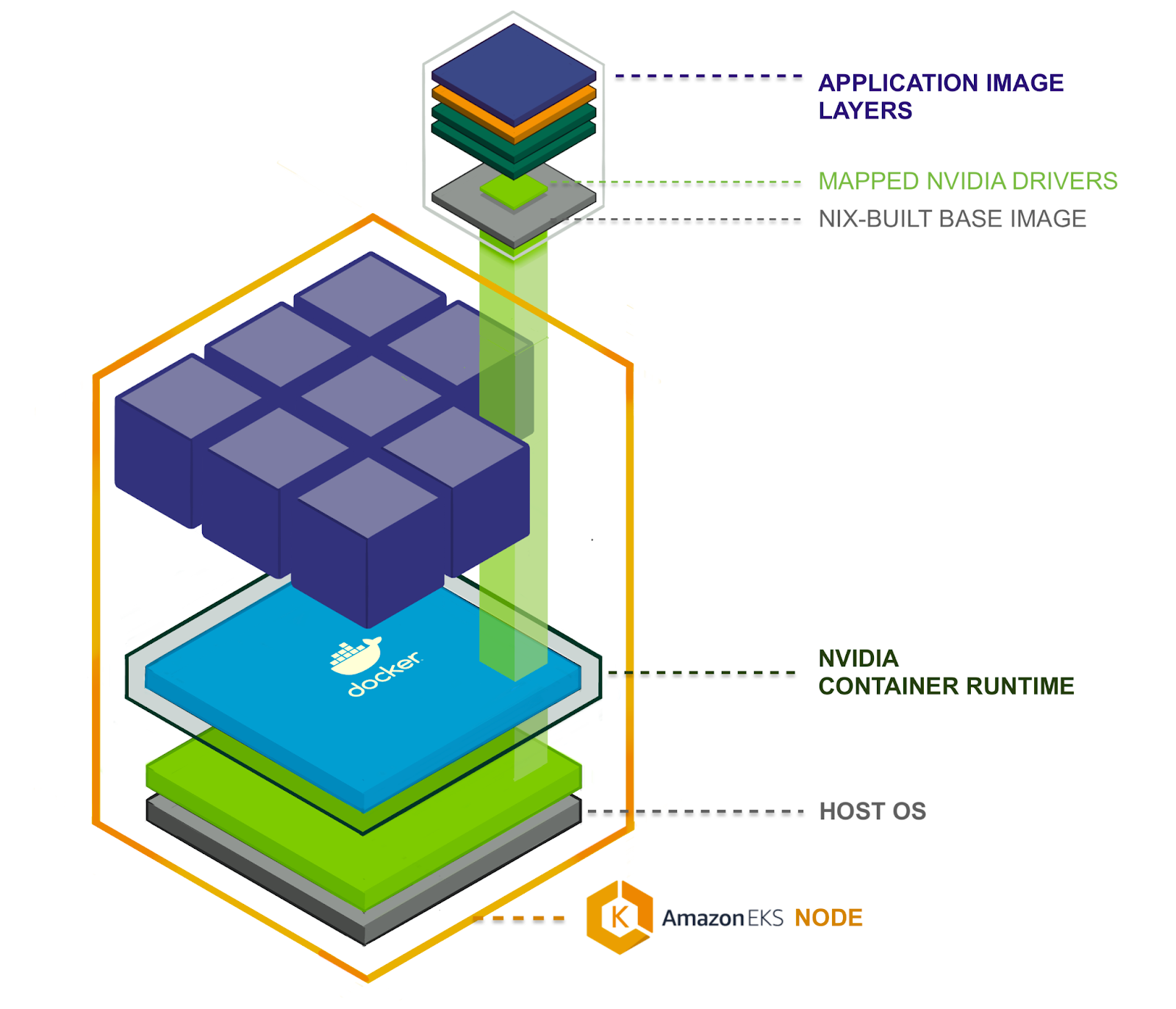
To provide an end-to-end explanation, each component is explored in order, starting with the host operating system in which our containerized ML applications run.
Host OS, drivers, and container runtime
Canva is an AWS shop and therefore uses Elastic Kubernetes Service (EKS)(opens in a new tab or window) to run K8s clusters. In 2018, EKS added support(opens in a new tab or window) for GPU-accelerated applications, introducing the 'EKS-Optimized AMI with GPU Support'. This Amazon Machine Image (AMI) became a younger, fatter sibling to the 'EKS-Optimized AMI', adding a few important components on top of its predecessor.
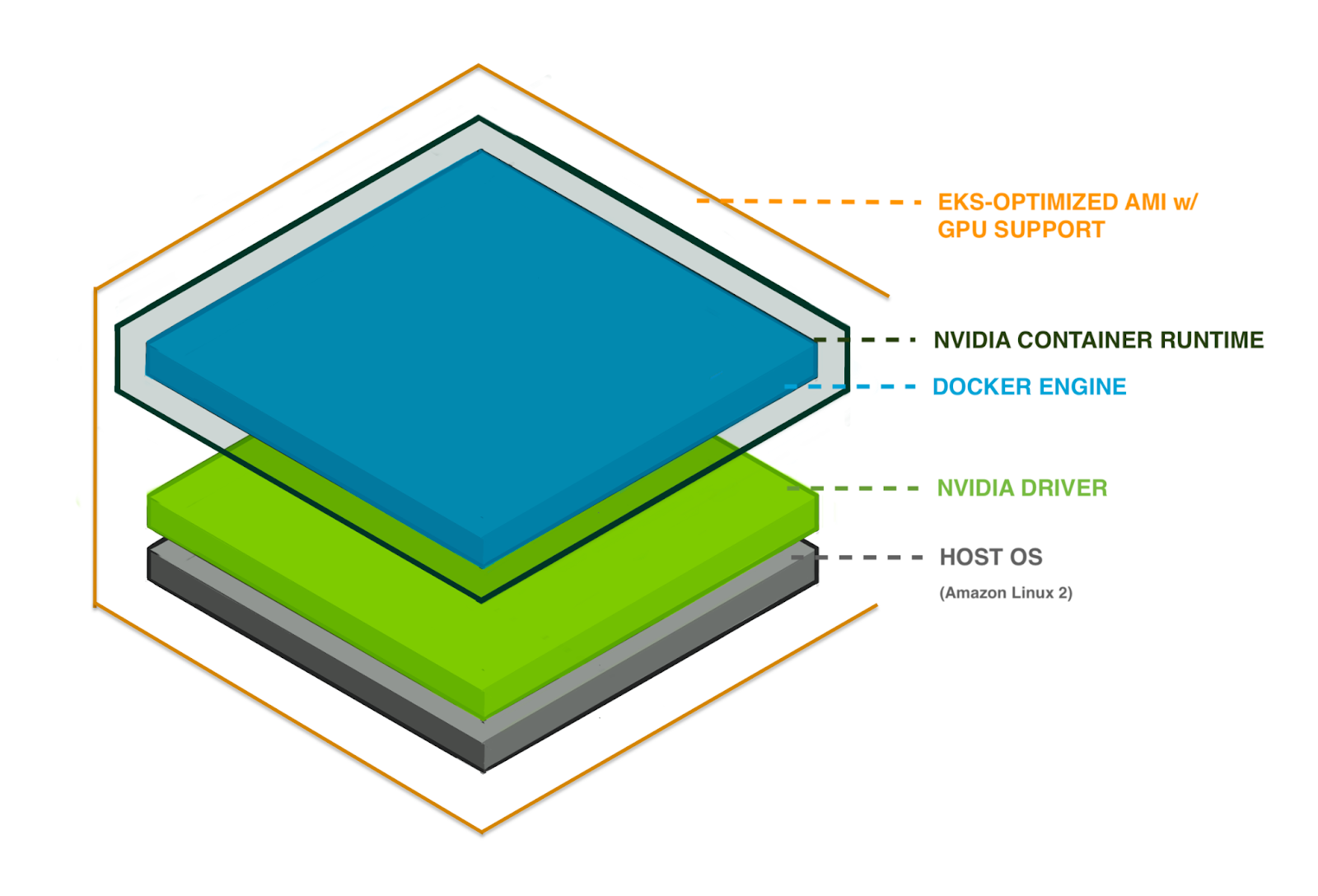
The host OS for the GPU-supporting AMI is Amazon Linux 2(opens in a new tab or window) (Amazon Linux 2018.03), just like the standard EKS AMI, but layered in are NVIDIA drivers and a container runtime. So the AMI contains the first few layered components in our GPU stack.
NVIDIA drivers, what are you?
The NVIDIA driver is something mentioned only vaguely in the documentation for PyTorch, EKS, NVIDIA, and Tensorflow. Is there one driver or many? If it's a singular driver, is that one file?
NVIDIA's documentation is disappointingly evasive on what the "driver" is, but we find a good answer in their official source code: NVIDIA/nvidia-docker/volumes.go(opens in a new tab or window).
In this Golang code, we have the VolumeInfo struct.
type components map[string][]stringVolumeInfo struct {Name stringMountpoint stringComponents components}VolumeInfo{"nvidia_driver","/usr/local/nvidia",components{…// — — — Compute — — -"libnvidia-ml.so", // Management library"libcuda.so", // CUDA driver library…}}
Inside the components map of the 'nvidia_driver' volume is a detailed view into what the NVIDIA driver actually is! The list of libraries is even broken down by NVIDIA container runtime "driver capability"(opens in a new tab or window) so we can understand what's needed for "Compute", the capability used when doing our model training.
The most interesting library components of the driver are
libnvidia-ml.so (Management library) and libcuda.so, the "CUDA
driver library" itself. The Compute section lists other libraries, but
they're mostly utility dependencies of libcuda.so.
Jumping onto one of our EKS cluster's GPU nodes we can validate the presence of these library files via
[ec2-user@ip-12—3—45—67 ~]$ ls -la /lib64/
Under /lib64, we find a bunch of CUDA or NVIDIA shared object library
files, including libcuda.soof course. libcuda.so is a symlink to the
versioned driver library file. Currently, our version is 460.73.01, and
so the versioned file is libcuda.so.460.73.01. Jumping on one of the
non-GPU cluster nodes, which use the basic 'EKS-optimized AMI', we don't
find these library files.
So that's the mysterious but all-important NVIDIA driver. What about the AMI's container runtime?
Container runtime
The NVIDIA container runtime is a direct dependency of the NVIDIA Container Toolkit. What's that? As stated on the project's README(opens in a new tab or window), it provides "a container runtime library and utilities to automatically configure containers to leverage NVIDIA GPUs." That library is "a simple CLI utility to automatically configure GNU/Linux containers leveraging NVIDIA hardware."
The nvidia-container-runtime itself claims to be a "modified version
of runC adding a custom pre-start hook to all containers". This allows
us to run containers that need to interact with GPUs. The default
version of runC can do a lot (see
Introducing runC: a lightweight universal container
runtime(opens in a new tab or window)), but it can't make NVIDIA's GPU drivers available to
containers, so NVIDIA wrote this modified version.
GPU device mounting in K8s
In this post's first diagram, we have a translucent green column extending from the host OS layer into the containerized application to indicate the mapped NVIDIA driver. This places the host's driver files into the container's filesystem. But a driver is no use without a device to drive. Something also needs to hook up the GPU device to the container.
Within K8s, the NVIDIA/k8s-device-plugin(opens in a new tab or window) does this. It is
responsible for mapping particular devices into the container's
filesystem at /dev/. It does not mount the NVIDIA driver library
files. Remember, that is handled beforehand by the NVIDIA container
runtime.
The k8s-device-plugin is a K8s Daemonset(opens in a new tab or window), which means at least one plugin server is run on each cluster node, cooperating with the node's kubelet(opens in a new tab or window). The plugin's responsibility is to register the node's GPU resources with the kubelet (which manages the running of containers in a pod on a single node), keep track of GPU health, and importantly for us, help the kubelet respond to GPU resource requests included in the container specs, which look like the following.
…resources:limits:nvidia.com/gpu: 2 # requesting 2 GPUs
When a node's kubelet receives a request like this, it looks for the
matching device plugin — in this case k8s-device-plugin — and initiates
an 'allocation phase' within which the device plugin sets up the
container with the GPU devices, mapping them into /dev/ in the
container's filesystem. On container stop, a 'prestop' hook is called
where the device plugin is responsible for unloading the drivers and
resetting the devices, ready for the next container.
Nix-based base images.
Having covered the host OS, drivers, special container runtime, and how GPU devices are connected to containers within Kubernetes, we have an idea of how a containerized process acquires driver files and gets hooked up to a host GPU device. But if our application code is going to find the GPU and enjoy accelerated number crunching, that containerized process must spawn from a valid image. Let's explore the container images that run our platform user's code, beginning with the Nix-built base layer provided by Canva's ML Platform team.
But first, I'll touch on why we'd want to construct our GPU base images
FROM scratch using Nix, and not just adopt the official NVIDIA
images.
Why build container images with Nix?
An OCI image is just a stack of tarballs, and though most people build
images from Dockerfiles, you don't have to. You can ditch the Docker
daemon and build application images in an
unprivileged container(opens in a new tab or window), or you can build images using Nix(opens in a new tab or window),
specifically Nix's dockerTools.buildImagefunctionality.
This is not the easiest way to acquire a GPU-supporting base image. The
easy way would be to use nvidia/cuda:11.2-cudnn8-runtime-ubuntu20,
which gets the job done. But within Canva's infrastructure group, we're
making long-term investments in Nix's reproducible build technology
for improved software security and maintenance.
Reproducible builds prevent software supply chain attacks. In non-reproducible build systems, some build input might become unknowingly and undetectably compromised, introducing vulnerabilities and backdoors into deployed software artifacts assumed safe and trusted.
Reproducible builds are also far more maintainable. Between organizations and within Canva itself, we can exchange build recipes that have sufficient detail for system understanding (know what you're using) and resistance against 'works on my machine' confusion. For more detail on why a company would invest in reproducible build infrastructure, see Buy-in — reproducible-builds.org(opens in a new tab or window).
With Nix, a purely functional package manager, we can begin to maintain understanding and control of our systems and step closer to realizing within the software industry the manufacturing industry's long accepted 'bill of materials' idea.
Nix dockerTools
Our Nix-built 'base images' use the aforementioned
dockerToolsfunctions provided by
Nixpkgs(opens in a new tab or window), a collection of over 80,000 software
packages that you can install with the Nix package manager. We attempt
to copy into our base images only what's needed to run the Python ML
applications targeting the platform. Jump into a shell on a running
container and you won't find tools such as tar or wget. Discerning what
was minimal and sufficient was challenging, and we didn't get it right
initially.
Breaking things
Partway into the project, we had a Nix-built base image with our application code and third-party packages layered on top. We shipped this to the cluster and ran the following program, shown right at the start of this post:
import torch; print(torch.cuda.get_device_name(0))
We expected "Tesla T4" as output, but saw the following instead.
returned 999 -> unknown error
Result = FAIL
Oops. We'd missed something important, but CUDA wasn't giving us any clues. A couple of us in the team poked around for a while, double-checking that all components but the base image were functioning correctly, and then tried to figure out what was unhelpfully different about our Nix-built image when compared to the official CUDA images.
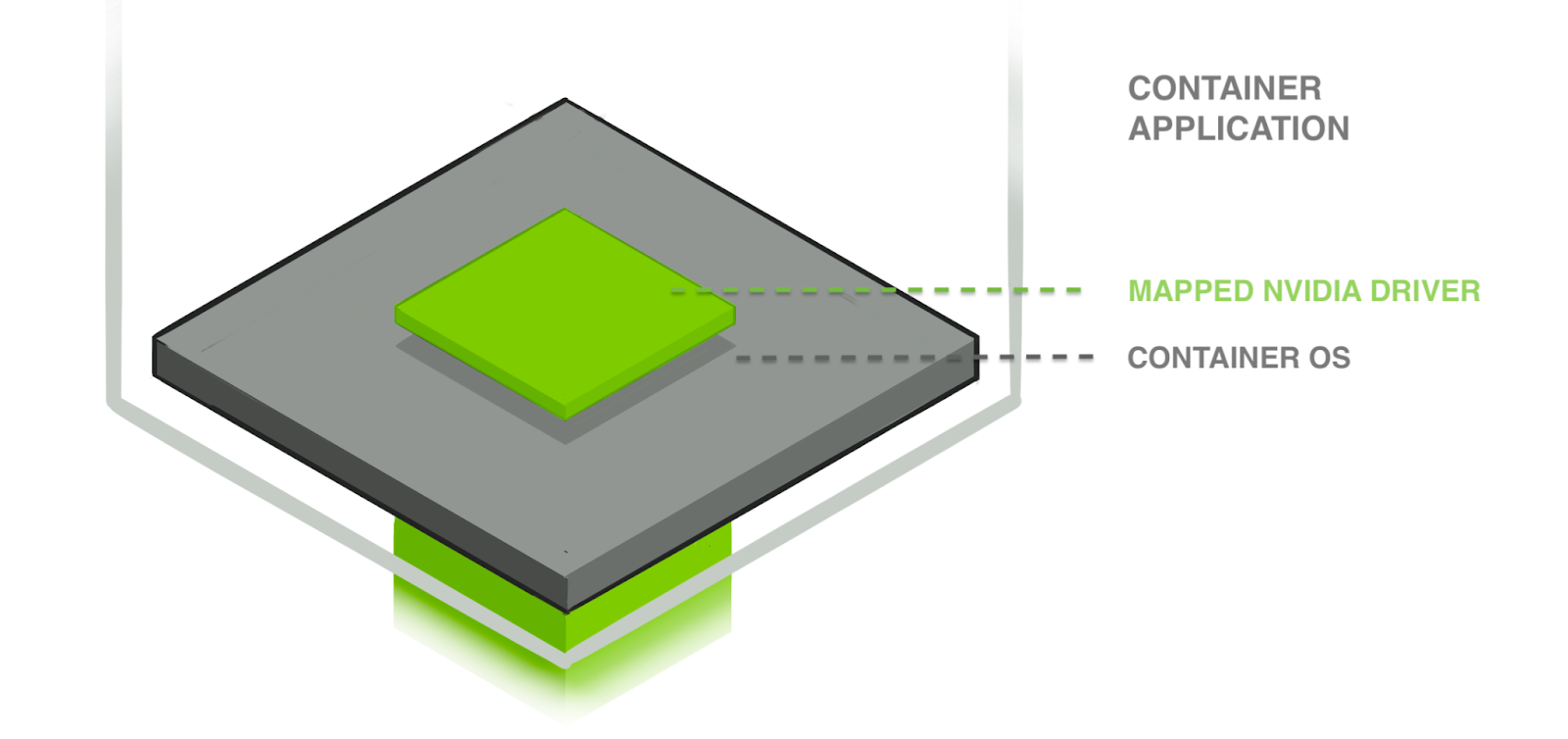
After figuring out exactly what the NVIDIA driver files were (detailed already in this post), we realized that they weren't being mapped into the container attempting to use the GPU. Why not?
It turns out that a base image must set
NVIDIA_DRIVER_CAPABILITIES=compute,utility
in its environment because the NVIDIA container runtime library looks at this to determine which libraries to mount inside a new container; it's a crucial environment variable.
You can check the official CUDA base images for the presence of these variables, which we did after discovering their importance to the container runtime.
$ docker pull nvidia/cuda:11.5.0-runtime-ubuntu18.04 && docker inspect -f \'{{range $index, $value := .Config.Env}}{{$value}}{{println}}{{end}}' \nvidia/cuda:11.5.0-runtime-ubuntu18.04 | grep NVIDIANVIDIA_REQUIRE_CUDA=cuda>=11.5 brand=tesla,driver>=418,driver<419 brand=tesla,driver>=440,driver<441 brand=tesla,driver>=450,driver<451
NVIDIA_VISIBLE_DEVICES=all
NVIDIA_DRIVER_CAPABILITIES=compute,utility
After fixing this, our image had the driver files mounted. We'd won the battle, but not yet the war. We had some more difficulty with our new Nix-built base image.
Nix, please play nice with Amazon Linux 2
Our other significant trouble stemmed from the fact that we are running
a 'distroless' Nix container on an Amazon Linux 2 host. The NVIDIA
container runtime 'maps' the driver files into a filesystem location
that works for standard Linux distros but not Nix, which roots all
system files under /nix/. We had to patch around this by adding
/usr/lib64/ to the LD_LIBRARY_PATH variable which otherwise only
included /nix/store/ paths. In general, patching around software that
isn't 'Nix aware' is a
curse of Nix(opens in a new tab or window) that you tradeoff
against Nix's benefits.
We also had to modify our base images to conform more closely to the
Filesystem Hierarchy
Standard(opens in a new tab or window), because CUDA and Python have hard expectations of the
presence of certain root directories, such as /tmp. Naturally, a
FROM scratch container image has no /tmp.
To our surprise, the container runtime also maps utility binaries, such
as nvidia-smi, into a container. But when trying to take advantage of
this utility to debug our GPU from within a container we got a confusing
error.
bash-4.4$ ls /usr/bin/nvidia-smi/usr/bin/nvidia-smibash-4.4$ /usr/bin/nvidia-smibash: /usr/bin/nvidia-smi: No such file or directory
We experienced this because our base images were shipping without a
dynamic linker, /lib64/ld-linux-x86-64.s0.2. Our Nix container image
config simply listed nothing that needed the linker. By using readelf
or just head -n 1, we could see that the mapped nvidia-smibinary
uses an absolute path reference to this linker file we failed to
provide.
No matter, just another modification to our Nix image to pull in the linker and symlink it into the expected Filesystem Hierarchy Standard location. For more on this gotcha, see Debugging a weird 'file not found' error(opens in a new tab or window).
The end result of our debugging and patching is that required library files sitting on our K8s node hosts are available within the container's filesystem and our engineer's GPU-accelerated application processes can find them at runtime.
Our simple PyTorch program now prints "Tesla T4".
PyTorch does B.Y.O. CUDA
With regained confidence in our base image layer, we finally arrive at the application image. We have two things to layer in: first-party application code and third-party PyPi packages. Copying in application code is straightforward, but there's a final interesting thing about this cloud GPU stack in the different runtime requirements of the Tensorflow and PyTorch packages.
At a high level, PyTorch 'bundles' its CUDA and CuDNN runtime libraries, but Tensorflow does not. Tensorflow's current runtime requirements are:
- NVIDIA GPU drivers — CUDA 11.2 requires 450.80.02 or higher.
- CUDA Toolkit (opens in a new tab or window)— TensorFlow supports CUDA® 11.2 (TensorFlow >= 2.5.0).
- CUPTI(opens in a new tab or window) (ships with the CUDA Toolkit).
- cuDNN(opens in a new tab or window) SDK 8.1.0 cuDNN versions.
PyTorch has only the first requirement, the NVIDIA GPU drivers, because
PyTorch's maintainers bundle the rest of the libraries into the Python
wheel package they distribute. You can see this by doing strace on a
Python program that imports PyTorch and runs torch.cuda.is_available()
to check for GPU accessibility. The trace shows the following
package-scoped GPU files being opened and read:
torch/lib/libc10_cuda.sotorch/lib/libtorch_python.sotorch/lib/libtorch.so: this file is huge, over 1GB on disk.torch/lib/libcudart-1b201d85.so.10.1: cudart → cuda runtime.
The program also eventually accesses
/usr/lib/x86_64-linux-gnu/libcuda.so, which is the NVIDIA GPU driver
dependency of PyTorch. The platform still needs to provide access to
this libcuda.so driver library for PyTorch to work with GPUs. It's not
bundled.
The upshot of this is that we can run GPU-accelerated PyTorch programs on our basic Python base image, which ships with no NVIDIA CUDA-specific libraries and runs about 80MB. Fat PyTorch wheels: very convenient for us, and quite a strain on the PyPI index's bandwidth.
Things are different for Tensorflow. Checking out an strace of
Tensorflow using the GPU, you find it accessing libraries that live on
the system — that is, in the OS runtime environment. With our Nix setup,
this looks like the following.
openat(AT_FDCWD, ‘c;"/nix/store/kcm...748y-cudatoolkit-11.2.1-lib/lib/libcudart.so.11.0", O_RDONLY|O_CLOEXEC) = 3uname({sysname="Linux", nodename="jono-base-python-cuda-demo", ...}) = 0openat(AT_FDCWD, "/usr/lib64/libcuda.so.1", O_RDONLY|O_CLOEXEC) = 3lstat("/usr/lib64/libcuda.so.1", {st_mode=S_IFLNK|0777, st_size=20, ...}) = 0readlink("/usr/lib64/libcuda.so.1", "libcuda.so.460.73.01", 4095) = 20lstat("/usr/lib64/libcuda.so.460.73.01", {st_mode=S_IFREG|0755, st_size=21795104, ...}) = 0openat(AT_FDCWD, "/nix/store/9q2...hwh-cudatoolkit-11.2.1/lib/libcublas.so.11", O_RDONLY|O_CLOEXEC) = 10openat(AT_FDCWD, "/nix/store/9q2...hwh-cudatoolkit-11.2.1/lib/libcublasLt.so.11", O_RDONLY|O_CLOEXEC) = 10openat(AT_FDCWD, "/nix/store/9q2...hwh-cudatoolkit-11.2.1/lib/libcufft.so.10", O_RDONLY|O_CLOEXEC) = 10openat(AT_FDCWD, "/nix/store/9q2...hwh-cudatoolkit-11.2.1/lib/libcurand.so.10", O_RDONLY|O_CLOEXEC) = 10openat(AT_FDCWD, "/nix/store/9q2...hwh-cudatoolkit-11.2.1/lib/libcusolver.so.11", O_RDONLY|O_CLOEXEC) = 10openat(AT_FDCWD, "/nix/store/9q2...hwh-cudatoolkit-11.2.1/lib/libcusparse.so.11", O_RDONLY|O_CLOEXEC) = 10openat(AT_FDCWD, "/nix/store/4ai7...kkb-cudatoolkit-11.2-cudnn-8.1.0/lib/libcudnn.so.8", O_RDONLY|O_CLOEXEC) = 10lstat("/usr/lib64/libcuda.so.1", {st_mode=S_IFLNK|0777, st_size=20, ...}) = 0
This strace output snippet shows the program accessing the core NVIDIA
driver libcuda.so as expected, but you can also see Tensorflow grab a
handful of other .so library files that were placed into the base
image using Nix. As mentioned previously, Tensorflow finds these files
by reading the LD_LIBRARY_PATH environment variable set in the base
image building process.
These differing runtime requirements see us maintain two Nix base images:
python39→ used by PyTorch (~80MB)python39_cuda→ used by Tensorflow (>1GB)
Our engineers must make use of the second image in their build file when they're using Tensorflow or other ML frameworks that don't bundle CUDA and CuDNN, such as Google's JAX(opens in a new tab or window).
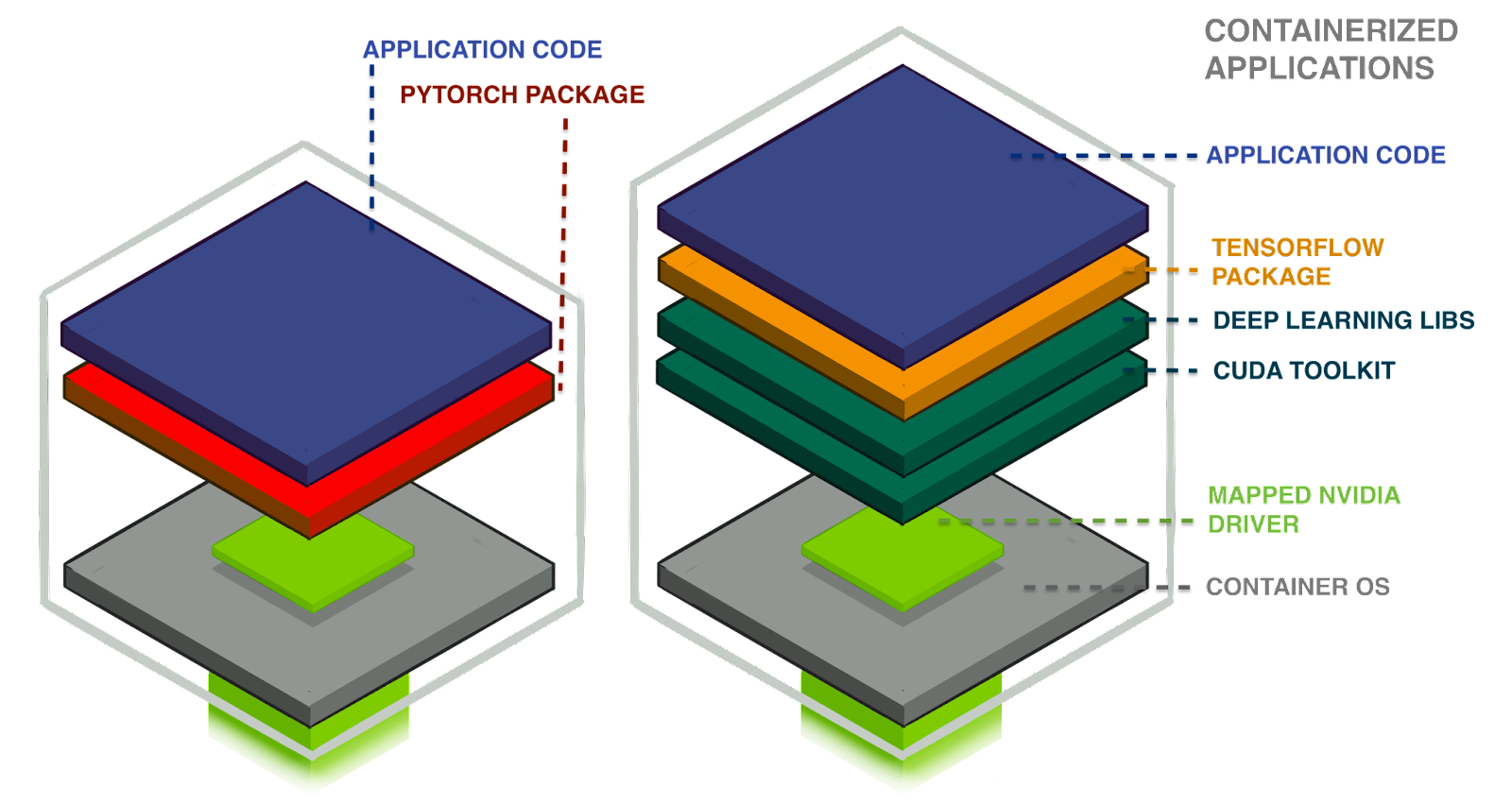
Putting it all together
You're at the end of a trip up and down our cloud GPU stack. A host K8s
node has the NVIDIA driver files and special GPU container runtime which
looks for an environment variable, NVIDIA_DRIVER_CAPABILITIES, telling
it to mount files from host to container. The node's kubelet and the
installed GPU device manager plugin manages the GPU devices themselves,
marrying them with containers needing mega-matrix-multiplying speed.
Assemble all this and you have the bare minimum GPU setup on K8s. And
remember, if you're just using PyTorch, that bundles its CUDA
dependencies so keep it simple and slim in the container base.
That's it. Before any deep learning wonderment begins, a program must first successfully find and access its Cloud GPU. Through rebuilding our base images component, we've become far more comfortable operating and modifying our GPU support system.
As of publication, this stack configuration has been in production for over 12 months but it will continue to grow and evolve as Canva matures into the Nix and Kubernetes ecosystems, because, as always, we're only 1% of the way there.
Acknowledgements
Thank you to Greg Roodt(opens in a new tab or window) and Nicholas Lambourne(opens in a new tab or window) for their essential contributions to this cloud GPU setup, and for their assistance in producing this post. Thanks to Grant Noble(opens in a new tab or window) and Paul Tune(opens in a new tab or window) for their editing contributions.
Interested in taking our ML Platform to the next level? Join us!(opens in a new tab or window)