Amazon S3
How Canva saves millions annually in Amazon S3 costs
Understanding our data and usage patterns was the real key.

Canva(opens in a new tab or window) is an online design tool that empowers users worldwide to design, edit and publish anything they can dream up. Canva runs most of its production workloads on AWS, leveraging several core services, including Amazon S3(opens in a new tab or window), Amazon ECS(opens in a new tab or window), Amazon RDS(opens in a new tab or window), and Amazon DynamoDB(opens in a new tab or window). Running on AWS has helped Canva move fast and keep up with the rapid scaling of our user base over the last 10 years. Since launching in 2013, Canva’s site has grown from humble beginnings to over 100 million monthly active users, who’ve created over 15 billion designs(opens in a new tab or window) together! Canva now has users across 190 countries, who design in over 100 languages(opens in a new tab or window) thanks to some amazing localization work(opens in a new tab or window) done by our Internationalisation team.
Canva designs usually begin from templates(opens in a new tab or window), allowing creators to easily pull in images, graphics, animations, and videos from our curated library of over 75 million stock photos and graphics(opens in a new tab or window). However, this number is relatively small compared to the total amount of content we store. This is because Canva allows every brand to create and publish their own templates, media, and other content, leading to an explosion of user-generated content that we need to store somewhere!
Amazon S3 provides a reliable, extremely durable, low-cost storage solution. In particular, Amazon S3 provides various storage classes designed for different access patterns and workloads. Understanding the differences between these S3 storage classes is crucial to operating cost-effectively at scale. Across Canva’s production environments, we store more than 230 Petabytes of data in Amazon S3, with our single largest S3 bucket coming in at a whopping 45 Petabytes! In this blog post, we’ll dive into how we have visibility over these vast quantities of data and how moving large amounts of this data to Amazon S3 Glacier Instant Retrieval(opens in a new tab or window) met our use cases and saved us millions of dollars annually.
Amazon S3 Storage Classes
Amazon S3 has several different storage classes you can choose from based on the data access, resiliency, and cost requirements of your workloads, as outlined in the following diagram.
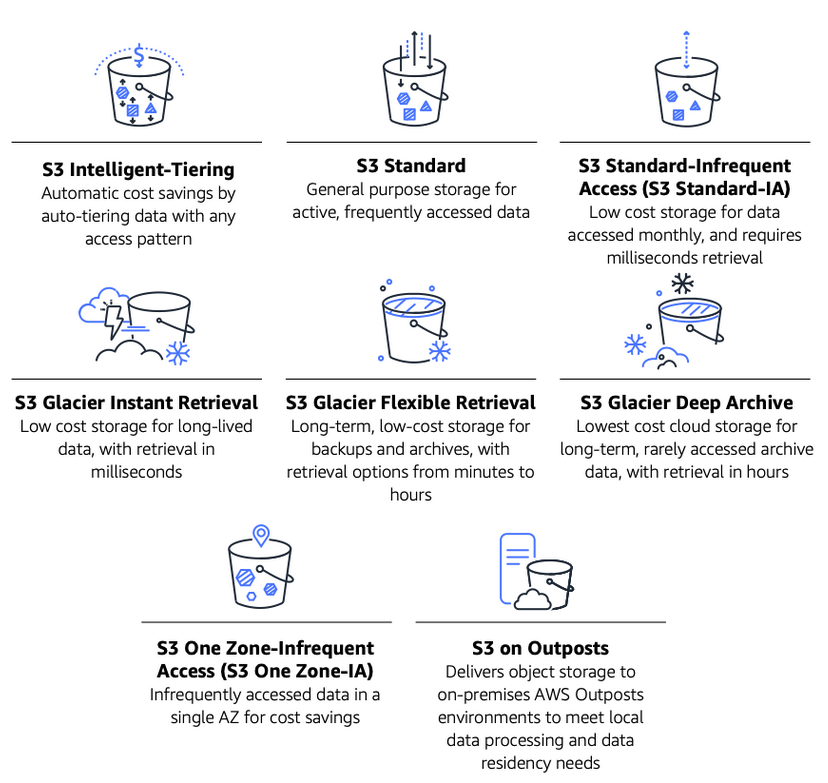
For Canva’s common libraries of templates, stock photos, and graphics, the S3 Standard storage class suits us best. Many users frequently access this content daily, so keeping it in a storage class optimized for frequently accessed data works perfectly. By contrast, users’ designs and the images and media they upload to them tend to be accessed within a short window of time. Users come to Canva, create their designs, present(opens in a new tab or window) or print(opens in a new tab or window) them, and usually don’t often return to old designs when finished. For this kind of content, we had historically opted to use the S3 Standard-Infrequent Access (S3 Standard-IA) storage class because it’s more cost effective than S3 Standard while still offering fast retrieval times. We’re simplifying a little here, so if you’re interested in a more complete picture of our diverse user base’s access patterns, have a read of our recent blog post “Understanding a Diverse User Base with Frequency Segmentation at Scale(opens in a new tab or window)”.
For some specific use cases, like log archival and backups, we also use S3 Glacier Flexible Retrieval. S3 Glacier Flexible Retrieval is ideal for data that can be retrieved within minutes to hours. This requirement is acceptable for log archives and backups, which may only need to be accessed on rare occasions, but generally isn’t suited for frequent access to user-generated content as we have with templates, stock photos, and graphics.
When AWS launched S3 Glacier Instant Retrieval in November 2021, it offered the best of both worlds for infrequently accessed data, low-cost archive storage, and fast retrieval in milliseconds. So naturally, this prompted us to ask ourselves how much we could save by migrating our infrequently accessed data to this S3 Glacier IR storage class. And which buckets should we migrate?
Understanding our Data
While we knew our user-generated content tended to be accessed soon after its creation, we weren’t entirely sure of the breakdown. We’d previously used S3 lifecycle policies(opens in a new tab or window) that would transition data from S3 Standard into S3 Standard-IA after 30 days but hadn’t analyzed that saving. A newly released tool that could give us some understanding in this space was S3 Storage Class Analysis(opens in a new tab or window), which we can turn on at a per-bucket level. Storage Class Analysis presents a few graphs that give valuable insights.
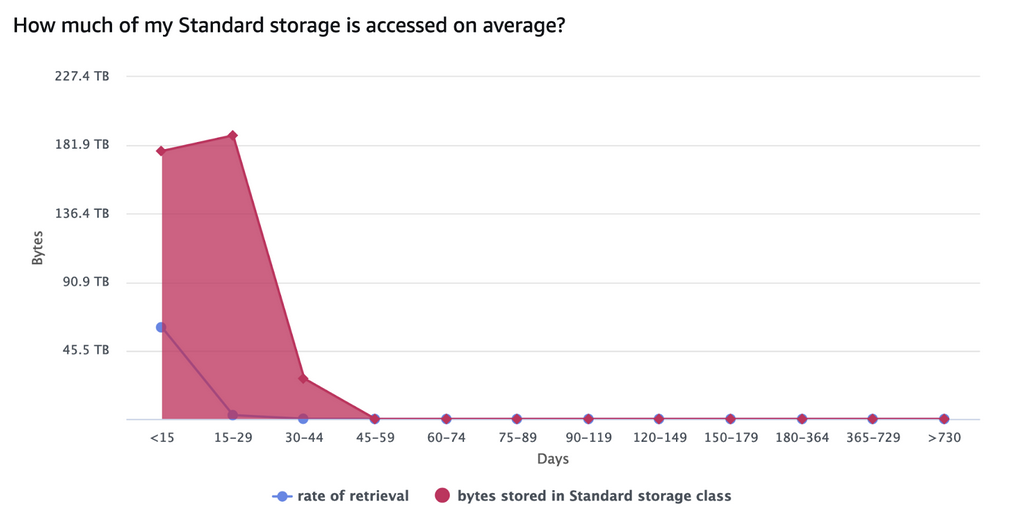
The following graph references data stored in S3 Standard only and shows the total bytes stored and the rate of retrieval broken down by age (that is, days since data creation). The total bytes stored drops off dramatically after 30 days because of the previously-mentioned lifecycle policy. The rate of retrieval also falls drastically after the first 15 days, in line with the expected access patterns we mentioned previously.
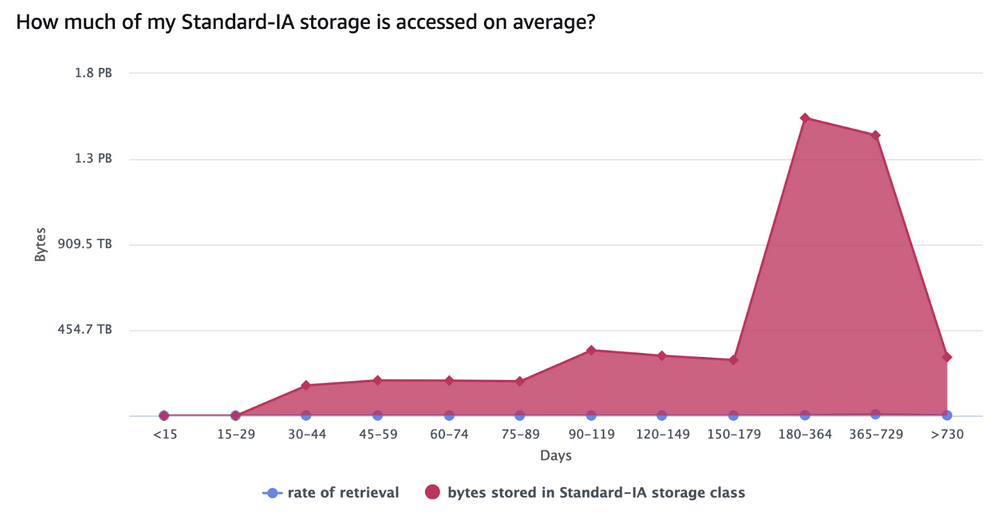
This next graph shows the same information, but for data stored in S3 Standard-IA. The bytes stored seem a bit strange, but looking closely at the Days axis, see that the time periods get longer (first 15 days, then 30, then 180, then 365). If you flattened this graph out to have equally spaced time periods, it would look very similar to Canva’s user growth over time. Importantly though, the rate of retrieval looks to be reasonably flat across all time periods.
The final graph in our analysis shows the total amount of data accessed across the bucket in each storage class. In this particular bucket, roughly 10% of the total data was stored in S3 Standard, while 90% was stored in S3 Standard-IA. The graph shows that 60-70% of all accessed data came from S3 Standard, while 30-40% came from S3 Standard-IA. This aligns very well with S3’s pricing model for the storage classes. S3 Standard has a higher storage cost per GB, but very low data access costs, while S3 Standard-IA (and S3 Glacier Instant Retrieval) has a lower storage cost per GB but higher data access costs.
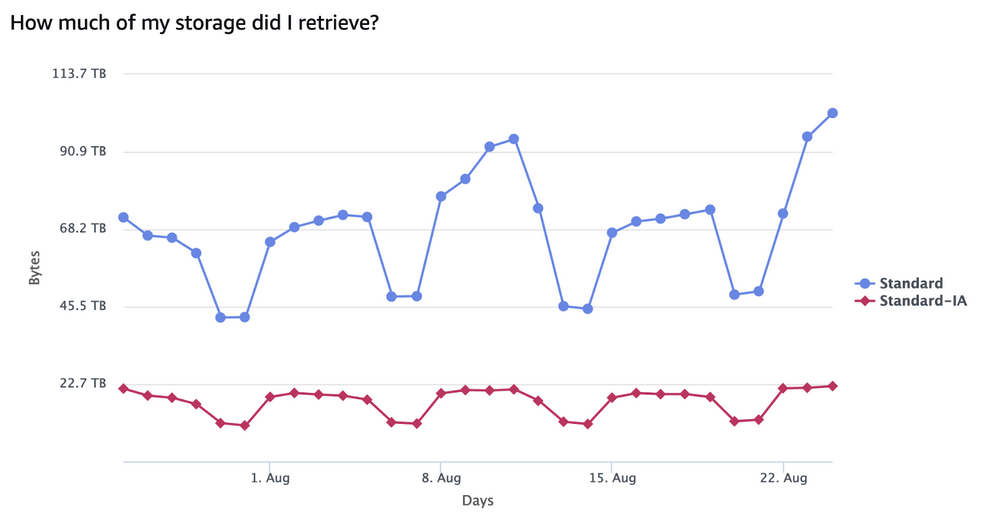
This kind of data access was typical for many of the buckets we used to store user-generated content. So surely we could add a lifecycle policy(opens in a new tab or window), transition everything to S3 Glacier Instant Retrieval and call it a day, right? Well, like everything in software, it depends.
Cost to Transition
When transitioning objects between S3 storage classes, you pay per request. For example, moving objects into S3 Glacier Instant Retrieval costs $0.02 per 1,000 objects. However, our S3 inventory at Canva contains over 300 billion objects, so transitioning everything without thinking about it would cost us over $6 million! This is another reason why it’s important to maximize storage cost visibility and have a good understanding of your data footprint.
Interestingly, this cost to transition is based on the number of objects we’re moving. At the same time, the potential savings from S3 Glacier Instant Retrieval largely comes from the total amount of data in the storage class. Furthermore, the cost to transition all the data is a one-time charge, while the savings from the cheaper storage class are ongoing.
This meant we could calculate the approximate time it would take to move from S3 Standard to S3 Glacier Instant Retrieval to break even based on the average object size in the bucket. For example, if you need to transition a small number of very large objects, the payoff happens quickly. Alternatively, transitioning a large number of small objects can take months before breaking even. We did the same analysis for S3 Standard-IA because we already had large amounts of data in the storage class for cost savings.
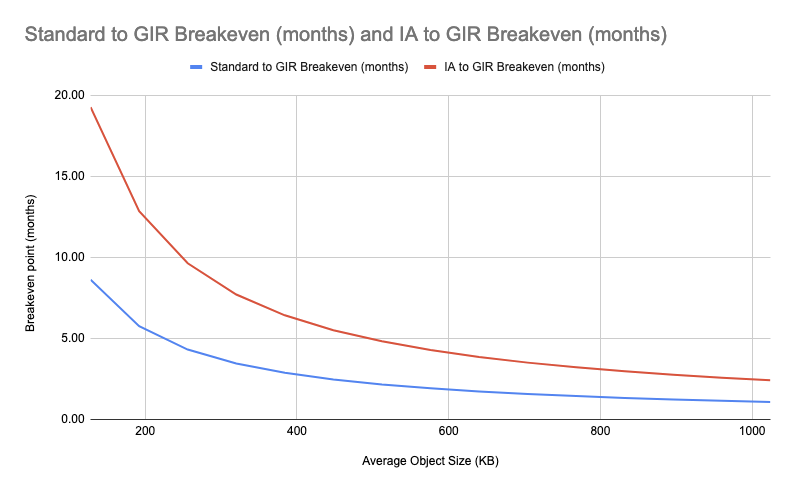
The graph’s x-axis begins on the left at 128 KB because that’s the minimum billable size of objects in S3 Standard-IA and S3 Glacier Instant Retrieval (even if your objects are smaller than 128 KB, you’re still billed for 128 KB). Therefore the time to break even when moving from S3 Standard IA to S3 Glacier Instant Retrieval is constant for objects below 128 KB because all objects are billed as being 128 KB. You can see this in the following graph.
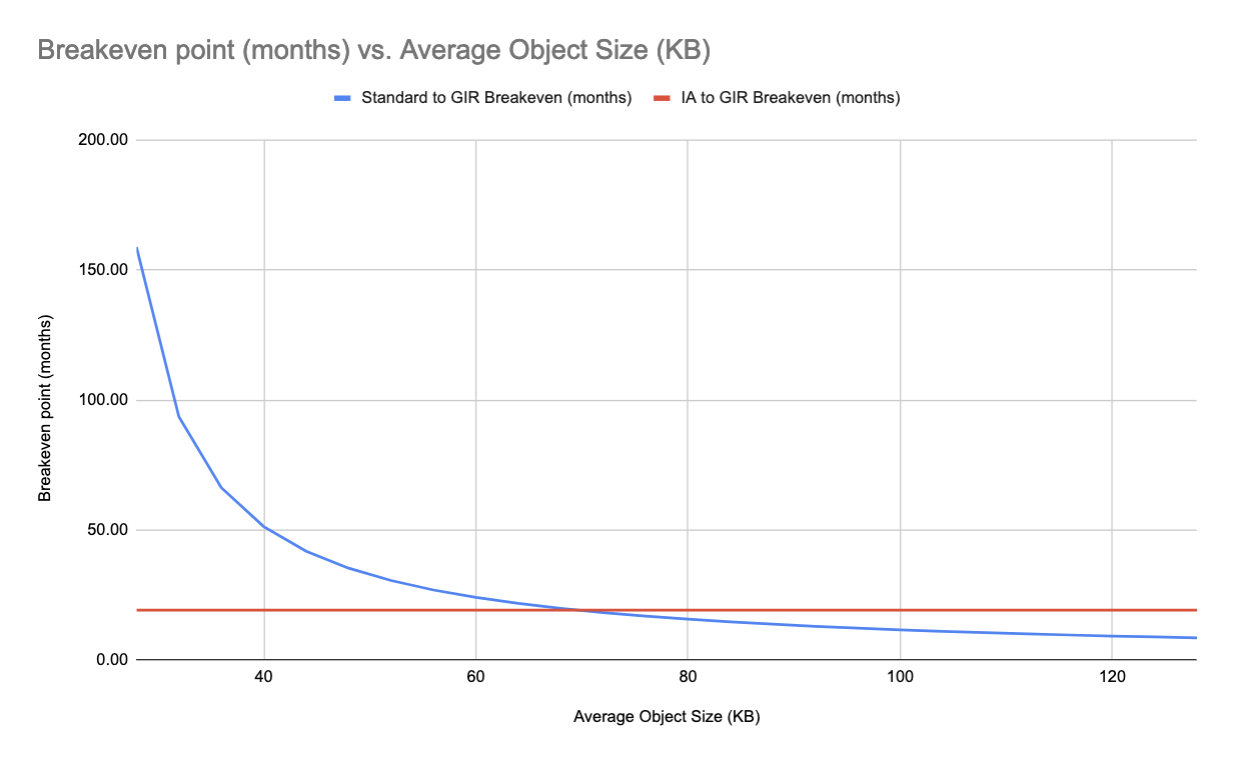
This graph explores the breakeven point for objects smaller than 128 KB. It’s important to note again that objects in S3 Standard-IA and S3 Glacier Instant Retrieval are always billed as though they are 128 KB. Therefore, there’s a point (around 20 KB) where it’s more cost-effective to store objects in S3 Standard than it is to store them in S3 Standard-IA or S3 Glacier Instant Retrieval.
The important takeaway is that we would see a positive return on investment from moving objects from S3 Standard IA to S3 Glacier Instant Retrieval faster on buckets with larger average object sizes. When we performed this analysis, we decided to target buckets (with the appropriate usage patterns from the previous section) with an average object size of 400 KB or more first because these buckets would show a positive return on investment within 6 months or less.
Conclusion
There’s very little to write about regarding the migration effort, which was an engineer’s dream! We applied a lifecycle policy to each of the buckets, and quickly migrated nearly 80 billion objects in approximately two days. At the time of writing this blog, roughly 130 petabytes of Canva’s total 230 petabytes of data in S3 resides in S3 Glacier Instant Retrieval. We have found it extremely valuable as a tool for reducing costs on our infrequently accessed user data. It offers the best of both worlds from S3 Standard-IA and S3 Glacier Flexible Retrieval.
Canva saves roughly $300,000 per month ($3.6 million annually) thanks to these changes, and given the ever-growing amount of user-generated data we store, these savings continue to grow over time. However, it’s very important to remember that these savings required us to first understand the access patterns for our data, as well as a one-off spend of over $1.6 million to transition roughly 80 billion objects. Overall this meant that we saw a positive ROI after only a few months of making the transition, which is still pretty fantastic!
AWS has been a great partner through all of this work and continues to invest in fit-for-purpose storage classes, to help customers with use cases at any scale. Thanks for reading this blog post!


