Search and Relevance
Search Pipeline: Part I
How we are rebuilding Canva's search stack and pipeline.

This two-part blog post details the challenges we faced within the Search and Recommendations group in building a scalable search architecture.
In part I, we'll discuss the challenges, and in part II, we'll break down the details of our search architecture, and how we take a platform-first approach to enable Canva to build a world-class search experience.
Background
Search is foundational to the success of Canva.
Whether you're creating your designs using the various editor ingredients, managing your private content, or seeking help during the process, accessing the right content quickly and efficiently is the key to a great user experience. Slow load times, irrelevant results, and unstable systems are the enemy of such an experience, and we seek to minimize such problems wherever possible.
Like many things in life, this is often easier said than done.
Canva Scale
At last count, we itemized nearly 50 unique entry points into our search systems, including template results, editor ingredients, help, content management systems, application search, and user feedback. That's not even counting our internal systems to ensure our users and content creators are kept happy. We also cover a large part of the public-facing user interface through input controls, presentation, and results filtering.
Search is everywhere.
On top of that, not only are our search surfaces expansive, but they're also busy. Our public content search can receive upwards of 20,000 requests per second at peak times. We aren't quite at Google or Bing scale yet, but we're still responsible for heavily trafficked services that need to keep running.
For the last nine months, a dedicated squad within Search Platform has worked on an improved operational process and better visibility into our systems. The fruits of this endeavor are showing, with a significant uplift in uptime and stable latencies. We also have observability dashboards through Datadog, Elasticsearch and Kibana, and Jaegar, which makes incident management easier.
So, where's the problem?
In short, the architecture.
Evolutionary Architecture
The Canva codebase, at some point soon, is going to celebrate a birthday that would make it eligible for high school. During those years, we've collected a quarter of a million commits, and this number only keeps growing.
The Search and Recommendations team comprises nearly 80 Canvanauts across several specializations, including machine learning, data science, operations, backend and frontend engineers, as well as leadership and management functions. For our search engineers, their primary responsibility, and where they get to express ideas and innovation, is in the search server. The search server is a large microservice (an oxymoron!) spanning many different responsibilities.
Within the search server, we had grown at least four different search systems, surfacing content for various ingredients and templates. Each search system is essentially a completely separate codebase with its own architecture, components, and conventions. There were some shared components between two systems (audio and font searches), but media and template searches existed as their own islands of functionality.
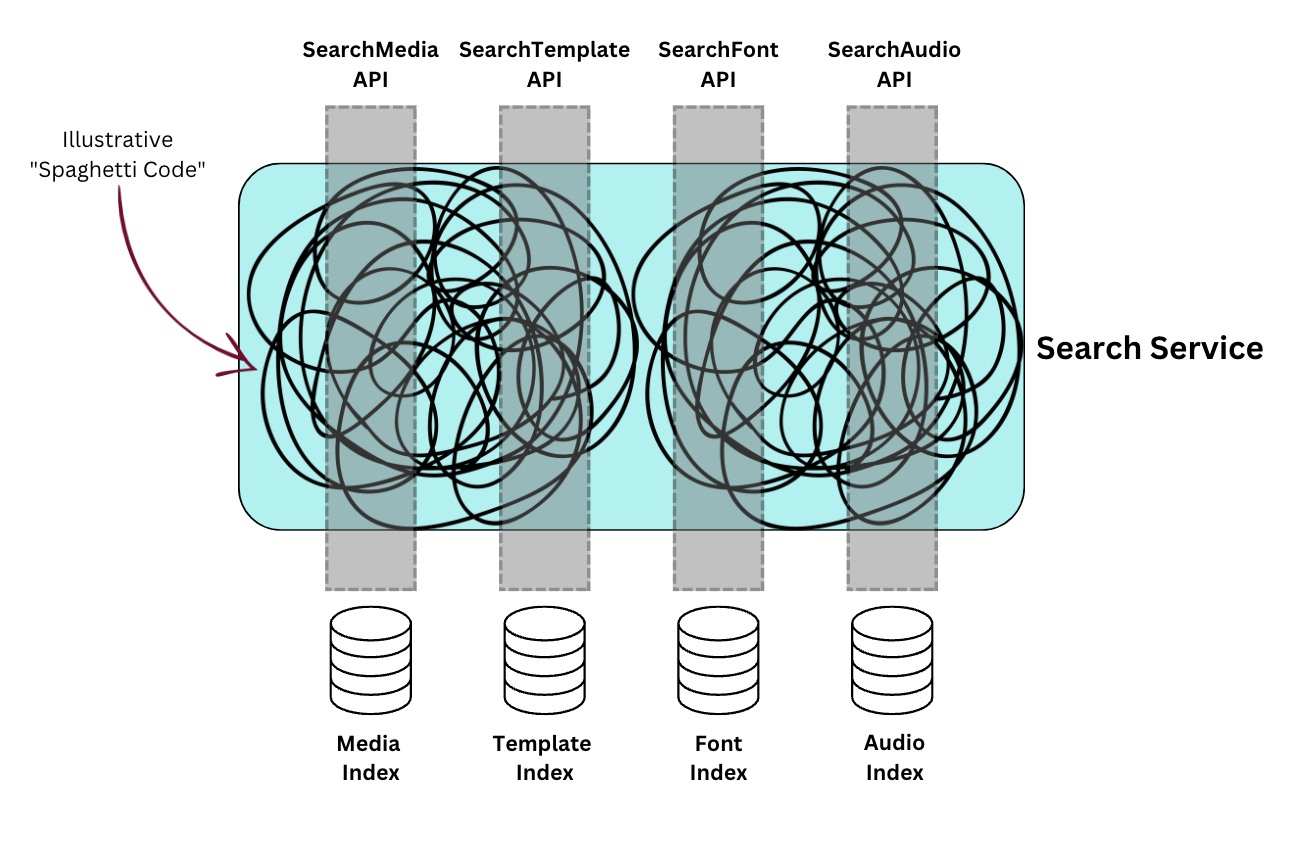
This kind of architecture is not uncommon nor unexpected; the big ball of mud architecture(opens in a new tab or window) is the most dominant architecture in existence. At Canva, we generally follow a WET (write everything twice) principle over DRY (don't repeat yourself). High-quality abstractions are hard to write, and become difficult to maintain if they're pulled in directions they weren't originally intended for. However, WEFT (write everything four times) indicated it was time for a refactor and a reimagining of the overall architecture.
We also had potential struggles ahead with implementing better experimentation. For example, how would we A/B test changes to translations, rewriting, or candidate generation if we have to build custom code for each system? How would we tackle interleaving experiments? Would we have to keep growing more and more search systems? All of these issues pointed toward future extensibility and maintenance problems.
We agreed we needed to move towards an architecture that we could share, and yet be flexible enough to accommodate the specialized parts.
Requirements
When designing the new architecture, we had to contemplate many requirements, the most salient of which are outlined in the following sections.
Componentization
As with everything in software, it's all about the interfaces, whether programmatic or human. Ideally, we would design stable and clean interfaces that promote reuse across many search systems. We should seek to implement good software design practices, notably taking heed of SOLID(opens in a new tab or window) principles and framework design guidelines.
The goal was to enable individual teams and developers to contribute to a shared codebase without stepping too much on each other's feet.
Debugging
Across each search system, we had many different responsibilities, including rewriting, spelling corrections, lookups into our category knowledge graph, elevated content, various experiments, and boost factors. We had no logging that allowed us to reason about how the final search query was created, or what happened after it was executed. This left us with, at worst, a black box, and at best, a long and complex search engine query to parse and try to correlate against system logs.
Fundamentally, this made it quite difficult for us to answer the simple question, "why did I get these search results?". This made it hard for our Search Quality team to debug issues and help our users.
The new architecture should overcome this significant limitation by providing a dedicated channel for components to write their explanation of what happened. We should also provide default log entries to capture orchestration and state changes to build a comprehensive view of the search request.
Observability
We should also ensure that the new architecture supports good observability, including system logs, metrics gathering and tracing. Ideally, this observability data would be automatically generated, with the option for individual engineers to hook in additional data if needed.
Machine Learning Integration
At Canva, we have millions of users who generate lots of data. We use this data to build machine learning models to enhance their experience. Some examples include:
- Stylistic clustering: Grouping images based on visual similarity.
- Personalization: Reasoning around individual user preferences based on interaction data.
- CTR: Discounted click-through rate and usage to build popularity signals for content.
- Semantic / Natural Language Processing (NLP) models over various metadata.
We wanted to ensure any new architecture could incorporate these machine learning models into results re-ranking.
Recommendations
A search query without user input can be considered a recommendation query. We generate such queries on page load or initialization of the editor panel. Even though the user might not have entered search text, we still have access to the surrounding context, for example, locale, subscription status, and user profile.
We believed that the new architecture could also benefit our recommendation systems. By building to the common interfaces, we could take advantage of the same components we built for search, most notably and importantly, the post-fetch re-rankers.
Design Considerations
Search Engine Migration
We built our existing search systems on Solr, but for many reasons, we decided to migrate to Elasticsearch 7.10(opens in a new tab or window), with a deployment target of AWS OpenSearch service. This migration was to happen in parallel, or at least shortly after, the migration to the new search architecture.
The existing approach heavily emphasized passing around a SolrQuery
builder object and then augmenting this through string manipulation. It
placed limitations upon querying a search engine with a different query
DSL, such as Elasticsearch.
One option was to continue to use the SolrQuery object and then write
an adapter to translate this query to an alternate form. However, this
would lock us into queries only expressible with Lucene syntax. This
syntax might leave us with limited options when querying vector data
stores or recommendation models, where the structure might look
radically different.
We needed to create a representation of query intent in a form that didn't tie us to a particular technology, allowing us to choose between alternate search engines more easily.
The Canva Search Domain
Canva is a visual communications platform allowing users to create designs from a vast library of media assets. There's a significant emphasis on ease of use and targeting a particular audience. Therefore, the way that users search for content is unique to us. It's also arguable that, over time, a user might also become trained to search in a specific way based on their interaction with the search systems.
Despite being a visual product, we rely heavily on full-text search over image metadata. We have several large libraries, such as Pexels(opens in a new tab or window), Pixabay(opens in a new tab or window), and Getty Images(opens in a new tab or window), where we can rely on the image metadata to be trustworthy. We also have in-house content teams responsible for ensuring this metadata is of high quality.
When contemplating the new architecture, we first examined the data collected from user interactions with the ingredients search and uncovered some interesting findings:
- Approximately
- 70% of queries are composed of single words. For example,
catordog. - 20% are two words. For example,
black catorbrown dog. - 10% are around four words in length, with some outliers.
- 70% of queries are composed of single words. For example,
- There are single-character queries, most notably in
Chinese, Japanese, and Korean languages. For example,
海and兔. - There are recurring queries. For example,
line,frame,arrow, andcircle. - Nouns are common, for example,
cat,dog, andsun, but there are some interesting exceptions:- Images of numerals (
1,2,3) - Concepts (
love,happiness, andjoy) - Formulae (
y = f(x)) - Smiles (
:)).
- Images of numerals (
- Use of advanced features like search syntax
(
brand:XYZABC) is less common. - The majority of users stop interacting with results after position 240.
No Silver Bullet
It was clear that there were several directions we could take with the
new architecture. The audio and font systems implemented a DAG-like
(directed acyclic graph(opens in a new tab or window)) system using
service resolution through Spring, while media and templates used an
imperative-style system that passed around SolrQuery objects.
We had many discussions on implementing a DAG system, as ultimately, it would provide us with the most flexibility. However, it would have some drawbacks, which we reasoned through below:
- We would be potentially limited to reuse at the individual node(s) level.
- Possible discoverability and comprehension problems since everything is some kind of node.
- Complexity in ensuring node input and outputs align and defining and visualizing the execution graph.
- Opportunity to accidentally introduce large computation workloads through forks.
- Less experienced engineers might struggle with the complexity.
With a better understanding of the complexity and challenges we faced, in part two we'll take a deep dive into the details of our new search pipeline architecture. Stay tuned for part II!
Acknowledgements
A huge thank you to the following people for their contributions to the search pipeline:
Dmitry Paramzin(opens in a new tab or window), Nic Laver(opens in a new tab or window), Russell Cam(opens in a new tab or window), Andreas Romin(opens in a new tab or window), Javier Garcia Flynn(opens in a new tab or window), Mark Pawlus(opens in a new tab or window), Nik Youdale(opens in a new tab or window), Rob Nichols(opens in a new tab or window), Rohan Mirchandani(opens in a new tab or window), Mayur Panchal(opens in a new tab or window), Tim Gibson(opens in a new tab or window) and Ashwin Ramesh(opens in a new tab or window).
Interested in improving our search systems and working with our architecture? Join Us!(opens in a new tab or window)


