Search and Relevance
Search Pipeline: Part II
More on how we are rebuilding Canva's search stack and pipeline.

In the first part of this blog post series, we discussed the challenges we faced with our current search architecture, the requirements needed for a new architecture, and the considerations to take into account in designing our new solution. In this second part, we'll dive into the details of our new search pipeline architecture.
Just Enough Architecture
Following many listening tours around the search and recommendations group, we entered an initial prototyping phase. Each engineer was free to tackle an area of architecture they felt most passionate about. This prototyping led to meaningful conversations around typed schemas, logging, state management, threading, and caching. Given the high likelihood of overlap in each implementation, this also gave us several options to consider.
After prototyping, we consolidated the "best" of each into an initial architecture; flexible enough to accommodate most of our use cases while being sufficiently opinionated to ensure easy comprehension and re-use.
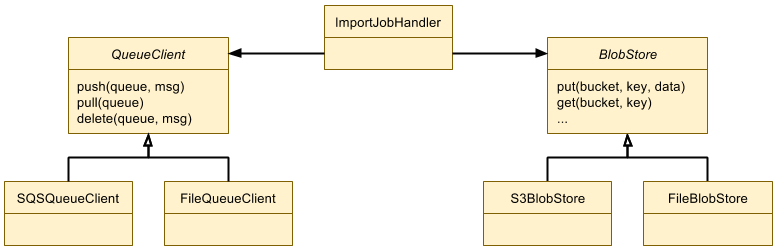
The search pipeline is made available as a series of Java packages that can be used across Canva. At the top level, a search pipeline is described by the following interface.
public interface SearchPipeline {SearchResults search(SearchQuery searchQuery, ExplainLogger explainLogger) throws SearchPipelineException;}
The default implementation of this interface orchestrates execution across its thread pools and automatically dispatches observability events.
Phases and Steps
We decided to model a search pipeline using clearly defined phases and steps, making it easier to communicate and reason about the flow of a search request through the system and align well with the different team specializations.
Each search pipeline is composed of a series of ordered and isolated steps, grouped within phases, as shown in the following diagram.
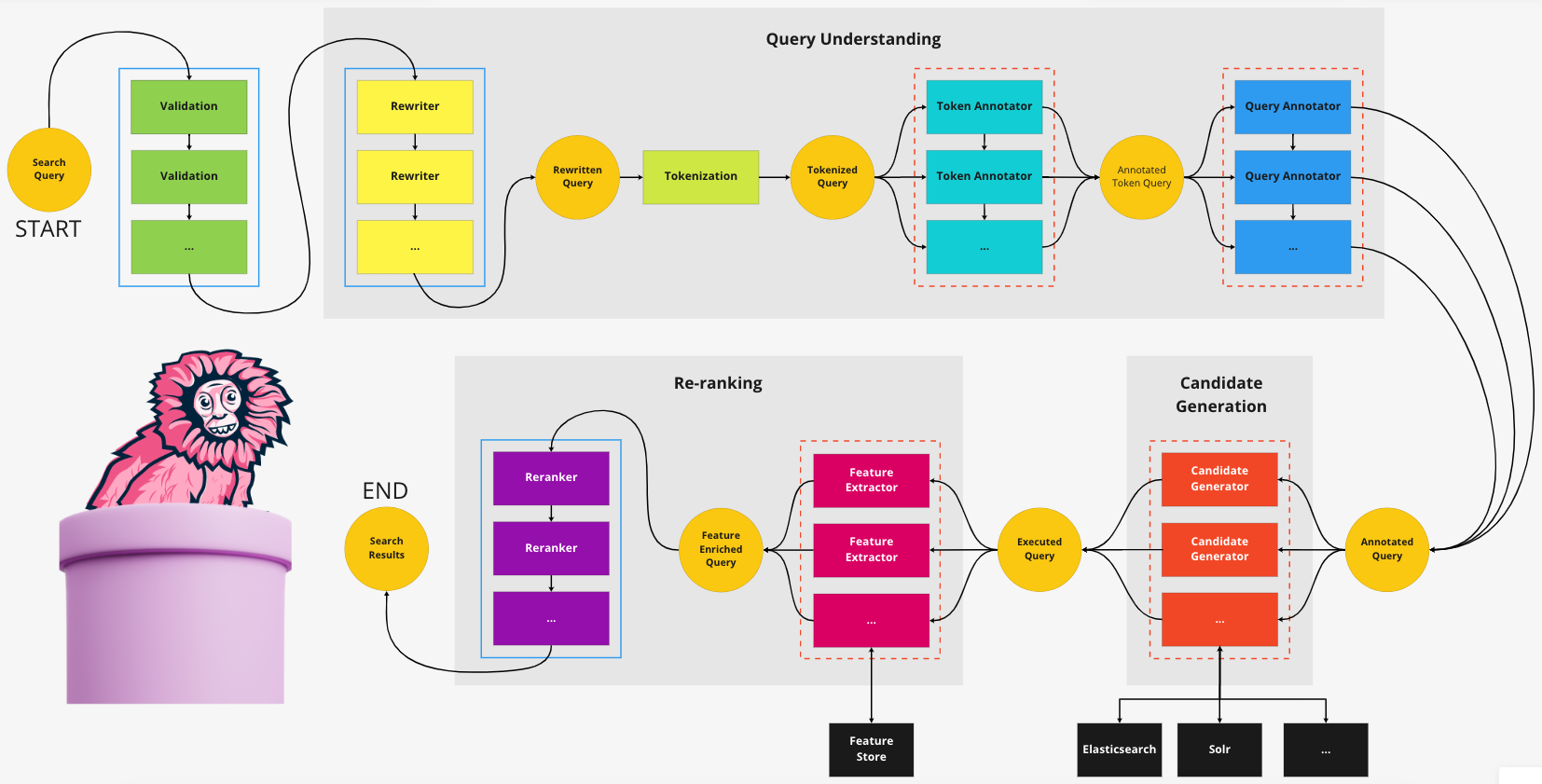
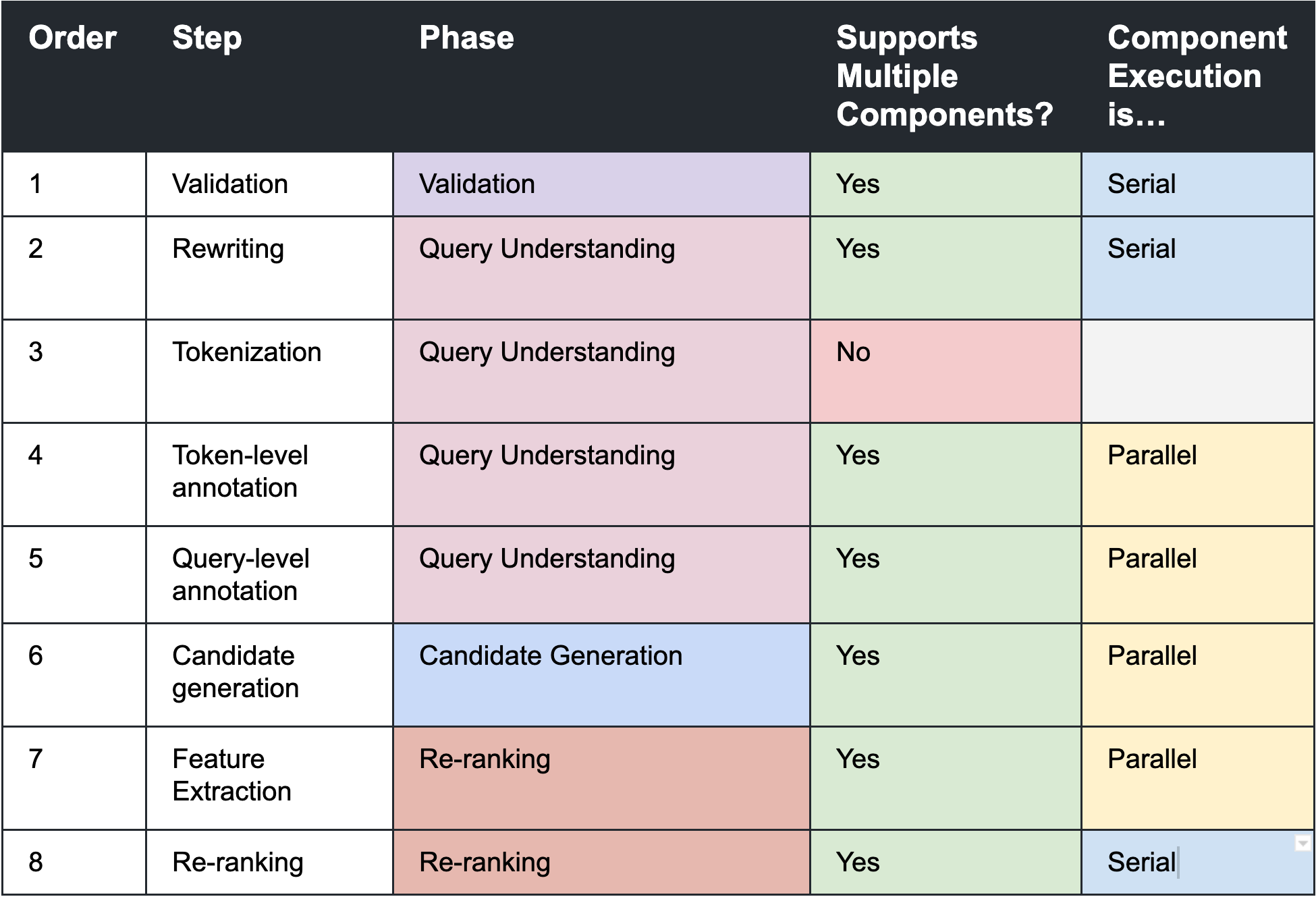
Some steps can be composed of multiple components, each of which contributes to the final output of that step. Each component within a step is:
- Isolated: Each component can read the output from previous steps, but it can't see other components participating in the current step. This allows us to take advantage of parallelism and not worry about sharing state between executing threads.
- Stateless: Each component should manage state out-of-process (for example, in Redis or DynamoDB). This allows us to, in the future, distribute and move computation around as we see fit.
- Transient: Components are not persistent or durable, which re-enforces the stateless property described previously.
The execution of the search pipeline is:
- Ordered: Each step occurs sequentially, components in each step either execute sequentially or in parallel as described in the table above.
- Immutable: It's not possible for steps to mutate state from previous steps.
Within a serially executed step, chains of components can be formed in any order and be considered valid. However, while valid, it's the responsibility of the author to consider whether the chosen chain of components within a serial step actually makes sense. We chose this approach to maximize the flexibility of possible components within the pipeline.
Each step is detailed in the following sections.
Validation
The pipeline can make use of validation components. Should any fail, the pipeline is halted. Validations are expected to be fast and ordered such that the fastest failing validators run first.
Examples of validators include:
- Page number to ensure we have reasonable constraints on the starting index.
- Page size to ensure we aren't requesting too many items.
Rewriting
A rewrite is a transformation of one query into another, most commonly modifying the query text. Rewriting is a highly-opinionated and lossy step; opinionated because it produces only one output and expects others to trust it, and lossy because such transformations are generally irreversible.
Types of rewriting include:
- A transparent rewrite preserves the original query, either by performing the rewrite to a different field, or overwriting the original query field, and copying the original query to another field. Downstream steps are expected to use the rewrite but have the option of referring to the original query, although this practice is somewhat discouraged because it introduces coupling to specific implementations.
- An opaque rewrite doesn't preserve the original query, thus forcing all downstream steps to use it.
- A forked rewrite splits into multiple branches, one for each rewrite output. For example, to run subsequent steps on both the original and translated text of ambiguous-language queries or ambiguous spelling corrections.
We chose to implement rewriters as transparent rewriters, where the downstream steps can inspect the before and after state of each rewrite. This allows for introspection on the prior state, for example, to examine the query text before translation takes place.
The pipeline supports an ordered list of rewriters, where tokenization and later steps use the final rewritten query as though it were the original.
Examples of rewriters include:
- High-confidence spell correction.
- High-confidence translation.
- Punctuation removal.
- Case normalization.
Tokenization
Given a rewritten query, the goal of tokenization(opens in a new tab or window) is to deconstruct the query text into smaller atomic text units that can be individually processed. A token consists of one or more characters and might contain whitespace or non-alphanumeric characters.
A simple example of tokenization would be to split the query text by whitespace into an array of tokens, perhaps choosing to group tokens delimited with double quotes as single tokens. However, there are more sophisticated tokenization techniques, including:
- Locale-specific tokenization, incorporating language rulesets.
- Semantic tokenization, for example, treating the queries independence day or seat belts as phrases, even without surrounding double quotes.
- Incorporating search syntax, allowing double quotes to treat phrases as single tokens.
Annotation
An annotation is metadata pertaining to the search query. We use annotations to provide additional query intent or understanding derived from the existing query context, often from external systems. The search pipeline supports annotations at two levels:
- Token Level: Annotations on a per-token basis.
- Query Level: Annotations that apply to the whole search query (with no reference to tokens) or annotations that incorporate more than one token (multi-token annotations).
Examples of annotations include:
- Named Entity Recognition(opens in a new tab or window) to extract entities relevant to Canva's domain
- Language Detection. For example
كلبcan be positively detected as Arabic, whilehuthas confidence values across numerous languages. - Classification of queries containing sensitive or problematic terms
- Synonyms(opens in a new tab or window) related to the query text.
When annotated, we have an object containing all of the intent we could infer from the query, modeled using the Java type system.
Candidate Generation
A candidate generator interprets an annotated query and formulates a request to a search engine or data store to retrieve results. Each candidate generator can interpret the annotated query differently, allowing us to make tradeoffs across recall and retrieval options.
We can register multiple candidate generators and have the pipeline coordinate the execution. This allows us to introduce various timings or result-count deadlines, for example, generate as many candidates as possible within 50ms. The results from each candidate generator and the resulting metadata is merged into an in-memory data structure for re-ranking.
We use various data stores, including: OpenSearch, Solr, and SageMaker. More recently, we've conducted investigations into vector data stores. Each data store holds a specialized corpus representation, with various optimizations made during indexing to make tradeoffs on recall or retrieval.
Feature Extraction and Enrichment
Following candidate generation, we seek to further build upon the candidate metadata before re-ranking takes place. We're in the process of building a high-performance feature store backed by Redis. In the meantime, we call into DynamoDB for these additional features.
A feature extractor is a component that, provided a given (query, document) pair, outputs one or more features. Some feature extractors might only depend on the query (query features), document (document features), or both (query-document features). A feature is typically a value object, for example, a boolean, numeric, or category type.
We can register many feature extractors in the pipeline, which are executed in parallel against the candidate list.
Re-ranking
The re-ranking step allows for fine-tuning the final order of candidates before returning them to the caller. This phase allows us to incorporate business logic and machine learning models better suited to post-fetch evaluation. This approach allows us to use BM25(opens in a new tab or window) search, while re-ranking through dense vector spaces.
We have multiple different re-ranking components, including:
- Business-rules: Results diversity, free or pro content, style, or any other business rule.
- Recommendation and Personalization: Optimizing the order based on user profile, ingredient popularity, or any number of machine learning models.
- Utilities: Because the pipeline can support multiple candidate generators, each creating their own group of candidates, some re-ranking components might merge or collapse these groups or operate on the resulting lists.
Complete Pipeline
An example of a search pipeline execution is shown in the following diagram.
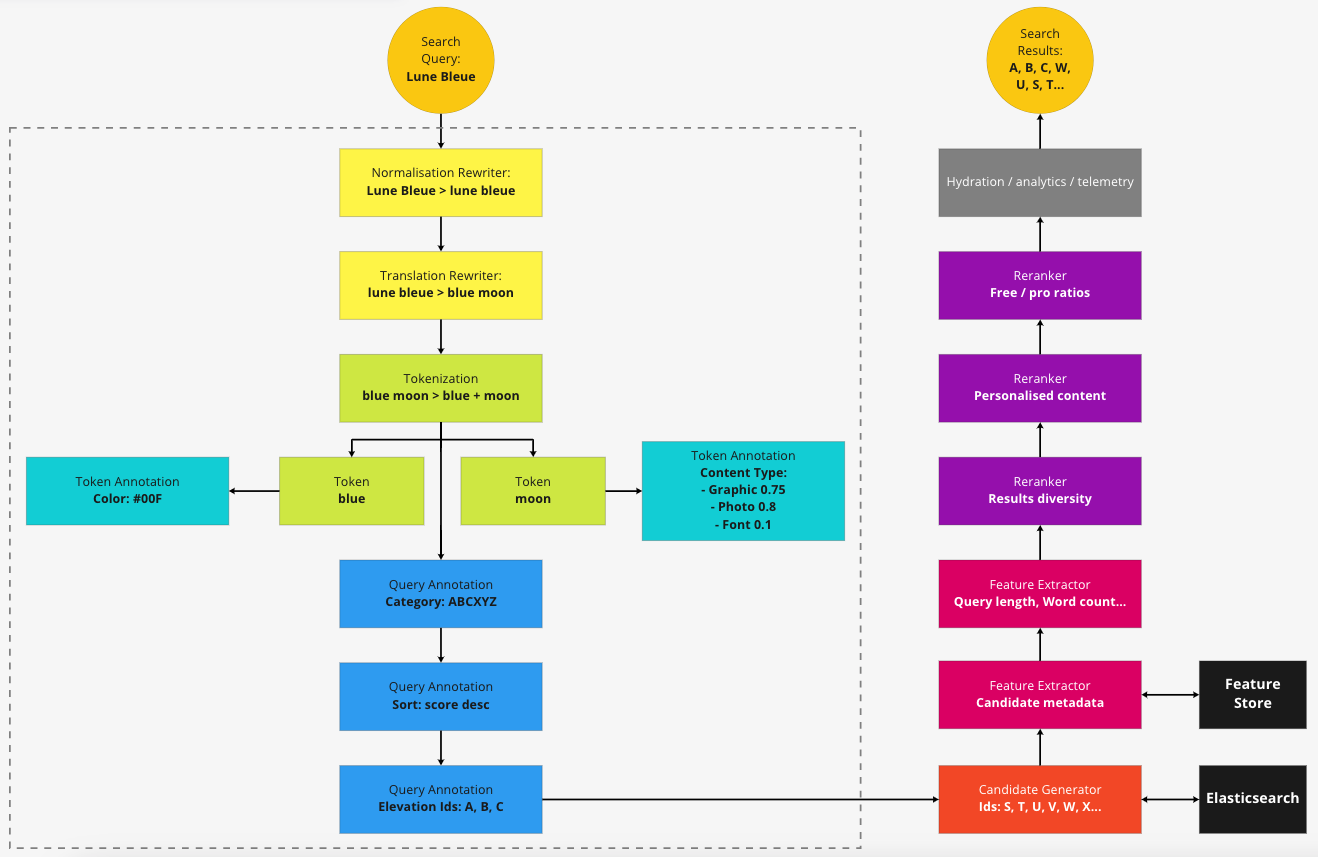
Pipeline as Unit of Work
We build and configure pipelines using a specification and factory, as shown in the following example.
var specification = new SearchPipelineSpecification("My Pipeline").withOrderedRewriters(Component.of(WhitespaceNormalizerRewriter.class, "whitespace"),Component.of(BlocklistRewriter.class, "blocklist"),Component.of(new SpellingCorrectionRewriter(new LocaleAwareReplacements(queryRewriteConfig::getSpellingCorrections),blocklistingService, this.flags), "spelling"),.withQueryAnnotators(NounPhraseSynonymQueryAnnotator.class).withCandidateGenerators(SolrCandidateGenerator.class).withFeatureExtractors(FeatureStoreExtractor.class).withOrderedRerankers(TopicalReranker.class));
This pattern allows us to encapsulate search logic into a single object, allowing us to build other abstractions, for example:
- Overfetching: Making tradeoffs between precision and recall dependent on the page index.
- Experiments: A/B testing and interleaving results between multiple pipelines.
- Caching decorators for components to bypass computation and retrieve from the cache instead.
- Cloning one pipeline from another, but with modifications.
Overfetching and Bots
We take different approaches to conducting a search depending on the requested page number and size. For the first set of 500 results, we prioritize precision, by running the full query understanding and re-ranking components, making heavy use of caching to ensure performance. We then slice into that result set for the first pages, allowing us to present the user with the best possible items on the first page ranked from the top 500 results.
For results beyond the scope of this overfetched set, we adopt a faster and more efficient pipeline, prioritizing speed over precision. The rationale is that very few users interact with results past around position 200, and the likelihood of us serving results to a bot is quite high.
Interleaving
Pipelines open up an efficient implementation of interleaving(opens in a new tab or window) for ranking experimentation. We will be writing a separate blog post on interleaving at Canva at a future date.
The Future
The new architecture also opens up additional possibilities for us in the future.
Distributed Execution
Given the componentized architecture and careful management of internal state, we can choose to deploy a search pipeline in various topologies. We could encapsulate the entire query understanding phase into a remote service call or deploy candidate generators into their own microservices.
Fault Tolerance
Because component execution is handled by the underlying pipeline implementation, we can introduce various fault tolerance strategies, including:
- Limiting Blast Radius: Should a component encounter or generate an exception, it's responsible for limiting its own blast impact on the pipeline. For example, if an annotator generates annotations that could be considered optional for candidate generation, the annotator should handle exceptions gracefully, return nothing, and log as appropriate.
- Deadlines: The pipeline could implement deadlines on various phases, steps, or components. Strategies include producing as many results as possible within a specified timeframe.
- Retries: Should a component fail or throw an exception, the pipeline could automatically retry that component should the error condition indicate a transient issue.
- Circuit breakers: We can create chains of components that execute according to failover rules. For example, run a Google translation rewriter unless we receive too many exceptions within a predefined window. At this point, we failover to an internal translation tool for a set time.
Summary
The new search pipeline at Canva has enabled us to standardize on an architecture. As a result we've been able to build a library of sharable components across multiple search experiences, dramatically shortening the time to deliver a new search system. We also reap the operational benefits from automatic telemetry and logging.
In migrating our architecture, we've developed a ubiquitous language that makes it much easier for the team to communicate with each other, using commonly understood terms. The impact of this should not be underestimated — a shared mental model is key to limiting inaccuracies and contradictions. We also have extensive documentation and inline Java docs to help engineers navigate the code.
So far, we've migrated our audio, font, video, and media search systems to the new architecture, with templates next. We've also migrated the audio and font search engines from Solr to Elasticsearch.
Acknowledgements
A huge thank you to the following people for their contributions to the search pipeline:
Dmitry Paramzin(opens in a new tab or window), Nic Laver(opens in a new tab or window), Russell Cam(opens in a new tab or window), Andreas Romin(opens in a new tab or window), Javier Garcia Flynn(opens in a new tab or window), Mark Pawlus(opens in a new tab or window), Nik Youdale(opens in a new tab or window), Rob Nichols(opens in a new tab or window), Rohan Mirchandani(opens in a new tab or window), Mayur Panchal(opens in a new tab or window), Tim Gibson(opens in a new tab or window) and Ashwin Ramesh(opens in a new tab or window).
Interested in improving our search systems and working with our architecture? Join Us!(opens in a new tab or window)