Backend Engineering
From Zero to 50 Million Uploads per Day: Scaling Media at Canva
The evolution of media persistence during hypergrowth at Canva

As a design tool, a huge part of Canva's value proposition is our library of more than 100 million stock photos and graphics and the ability to upload your own.
Canva launched in 2013 with a library of photos and graphics and the ability for users to upload their own to use in their designs. Canva's user base has expanded rapidly since: we now have more than 100 million monthly active users, and Canva users upload 50 million new media every day. To support this rapid growth — while keeping Canva up for our users 24x7 — we've had to continuously evolve the way we store media at Canva.
Canva's microservices and the media service
We built Canva with a microservices architecture, with most services being resource-oriented, managing operations on different resources within Canva, for example, users, documents, folders, and media. Services expose an API, have isolated persistence, and are each owned by a small team of engineers.
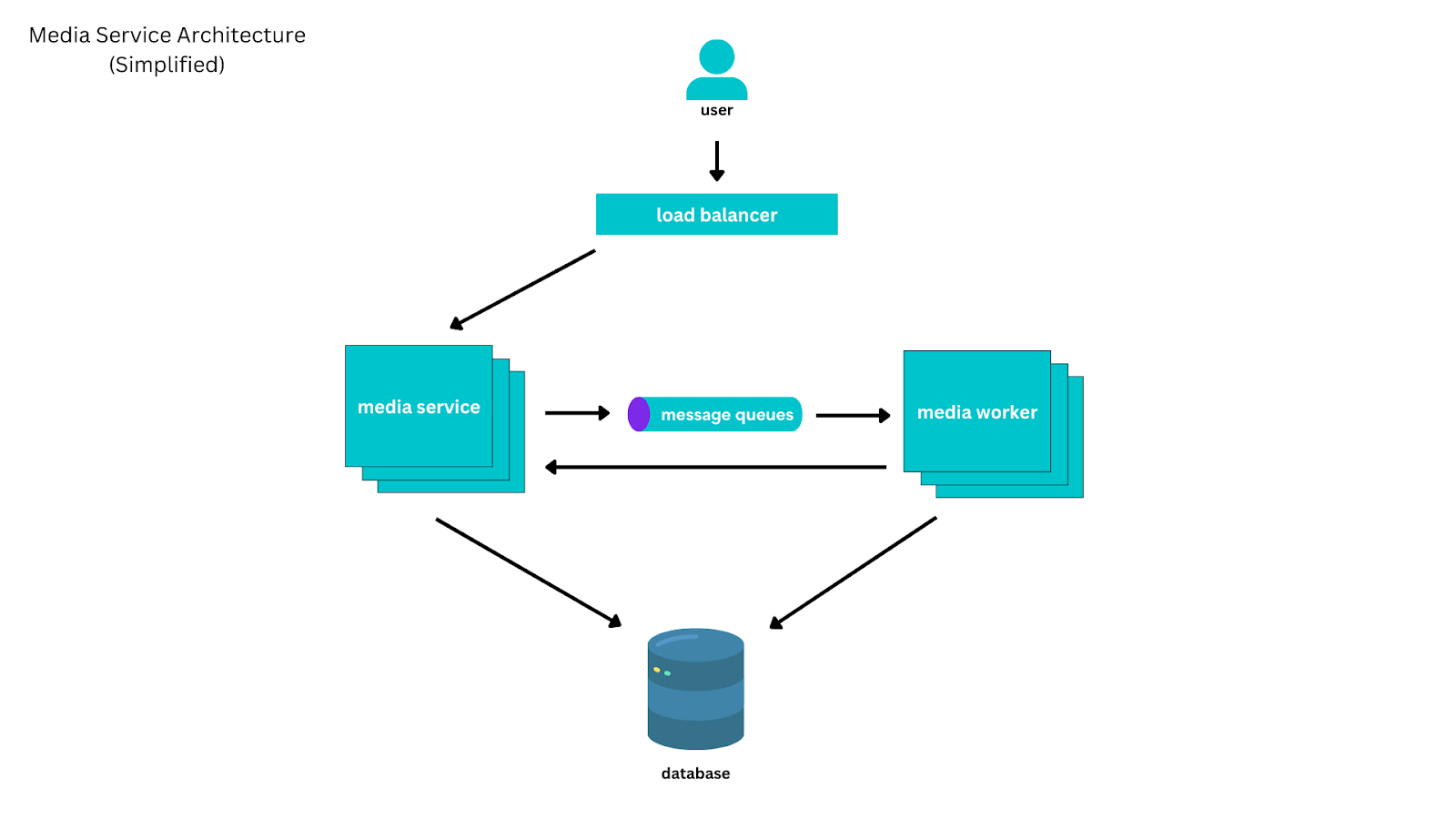
Canva's media service manages operations on and encapsulates the state of media resources. For each media, the service stores:
- Its ID.
- The owning user.
- Whether it's part of Canva's media library.
- External source information.
- Its status (active, trashed, or pending deletion).
- An extensive set of metadata about its content, including title, artist, keywords, color information.
- A reference to the media's files and where they're stored.
The media service serves many more reads than writes, and most media are rarely modified after they're created. Most media reads are of media that were created recently, except for media in our library of stock photos and graphics.
MySQL at Canva: Growing Pains
For much of Canva's history, most resource-oriented microservices were thin layers around MySQL hosted on AWS RDS, which was sufficient for all but the busiest services. Initially, we scaled the database vertically by using larger instances, and later horizontally, introducing eventually consistent reads to some services powered by MySQL read replicas.
The cracks started to show when schema change operations on our largest media tables began to take days. Later, MySQL's online DDL operations caused performance degradation so severe that we couldn't perform them while also serving user traffic.
Luckily for us, it was around this time(opens in a new tab or window) that the gh-ost(opens in a new tab or window) project became popular, allowing us to safely perform online schema migrations without user impact. Unfortunately, further issues rapidly arose, including:
- Hard limits on MySQL 5.6 replication rate imposed a ceiling on the rate of writes to our read replicas.
- Even using gh-ost, schema migrations eventually took up to six weeks, blocking feature releases.
- We were approaching the limits of RDS MySQL's EBS volume size at the time (16TB).
- We observed that each increase in our EBS volume size resulted in a small increase in I/O latency, which greatly impacted our tail latencies for user requests.
- Servicing our normal production traffic required a hot buffer pool, so instance restarts and version upgrades weren't possible without accepting some downtime.
- Because we created our RDS instances from snapshots with an ext3 filesystem, MySQL table files were limited to 2TB(opens in a new tab or window).
Investigating Alternatives and Bridging the Gap
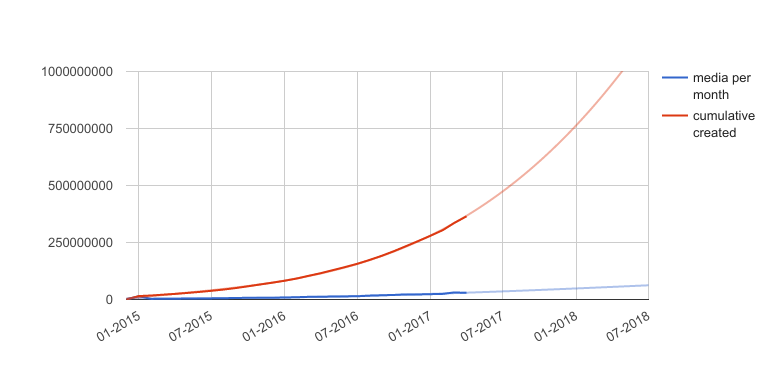
In mid-2017, with the number of Canva media approaching 1 billion and increasing exponentially, we began to investigate migration paths, with a strong preference for incremental approaches that would allow us to continue to scale and not put all of our bets on a single unproven technology choice.
At this point, we took several steps to extend the lifetime of our existing MySQL solution, including:
- Migrated media content metadata, the most commonly modified part of the schema, into a JSON column, with its own schema managed by the media service itself.
- Denormalized some tables to reduce lock contention and joins.
- Removed repeated content (for example, s3 bucket names) or encoded it in a shorter representation.
- Removed foreign key constraints.
- Changed the way we imported media to reduce the number of metadata updates.
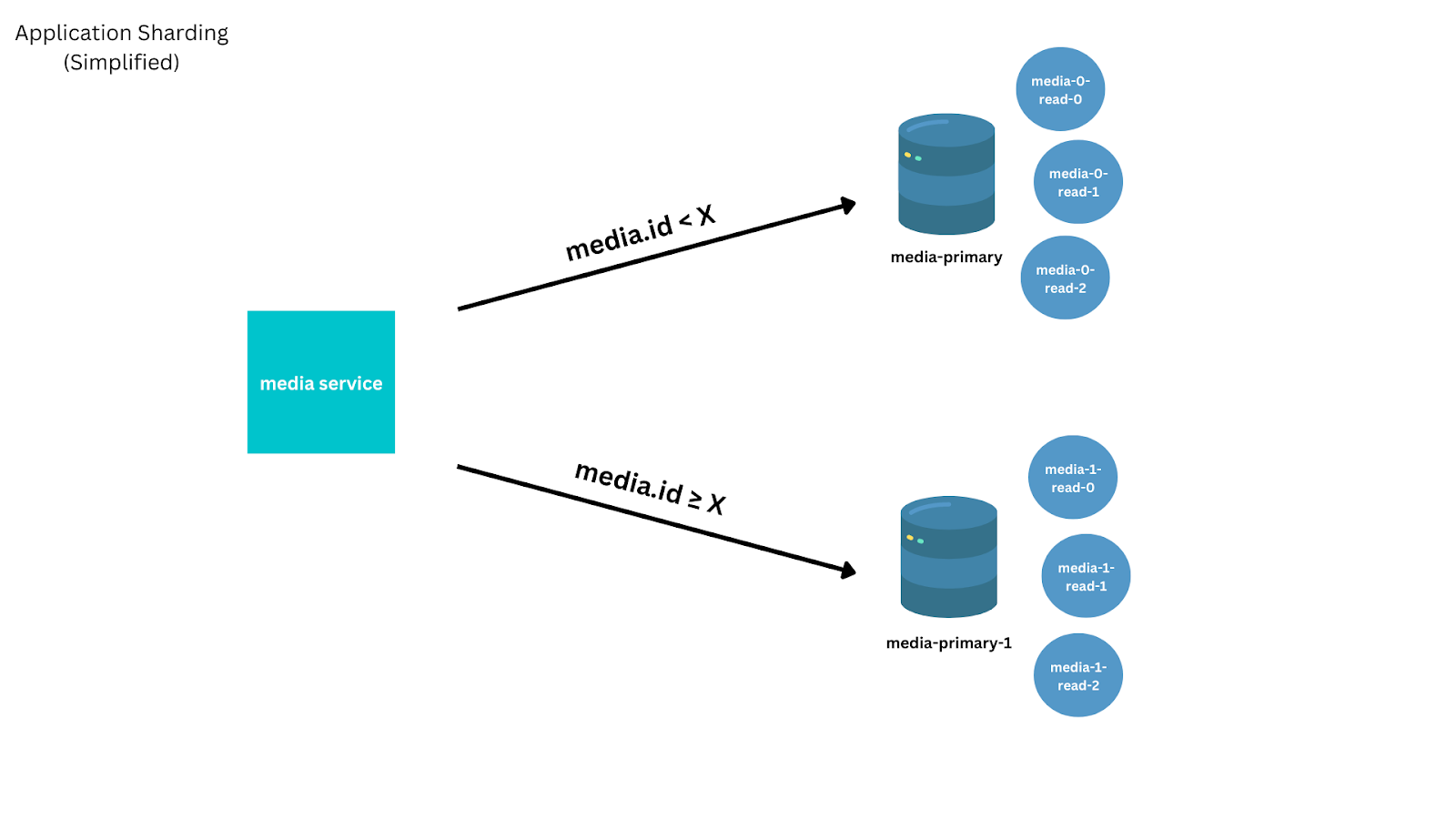
Towards the end of the lifetime of our MySQL solution, to avoid the 2TB ext3 table file size limit, avoid the replication throughput ceiling, and improve performance for our users, we implemented a simple sharding solution. We optimized the solution for the most common request, lookups by ID used when loading designs, but which required inefficient scatter gather queries for less common requests, like listing all media owned by a user.
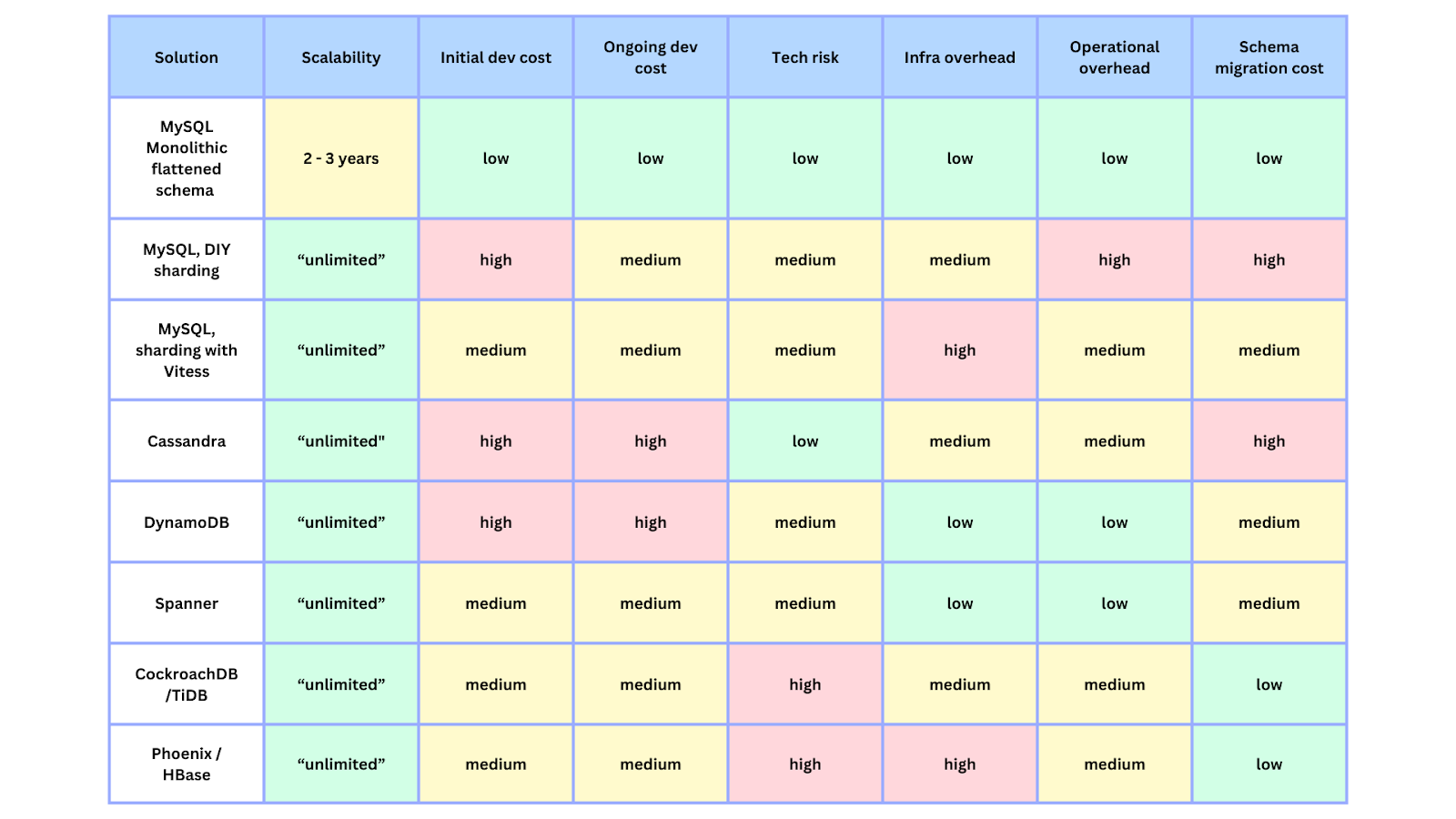
In parallel, we investigated and prototyped different long-term solutions. With a short runway, a preference for a managed solution, previous experience running (less complex) DynamoDB services at Canva, and having been able to prototype the solution, we chose DynamoDB as our tentative target. However, we knew we needed more work to prove it with the actual workload. We also needed a migration strategy allowing us to migrate without impacting users and cut over with zero downtime. The table below is a snapshot of our early thinking in this process.
Migrating Live
In designing the migration process, we needed to migrate all old, newly created, and updated media to DynamoDB. But we also sought to shed load from the MySQL cluster as soon as possible. We considered numerous options for replicating data from MySQL to DynamoDB, including:
- Writing to both datastores when handling a create or update request.
- Constructing and replaying an ordered log of all creates or updates.
- AWS DMS.
We decided on an approach that would:
- Give us complete control over how we mapped data into DynamoDB.
- Allow us to progressively migrate live.
- Shed load from the MySQL cluster as early as possible by migrating recently created, updated, and recently read media first.
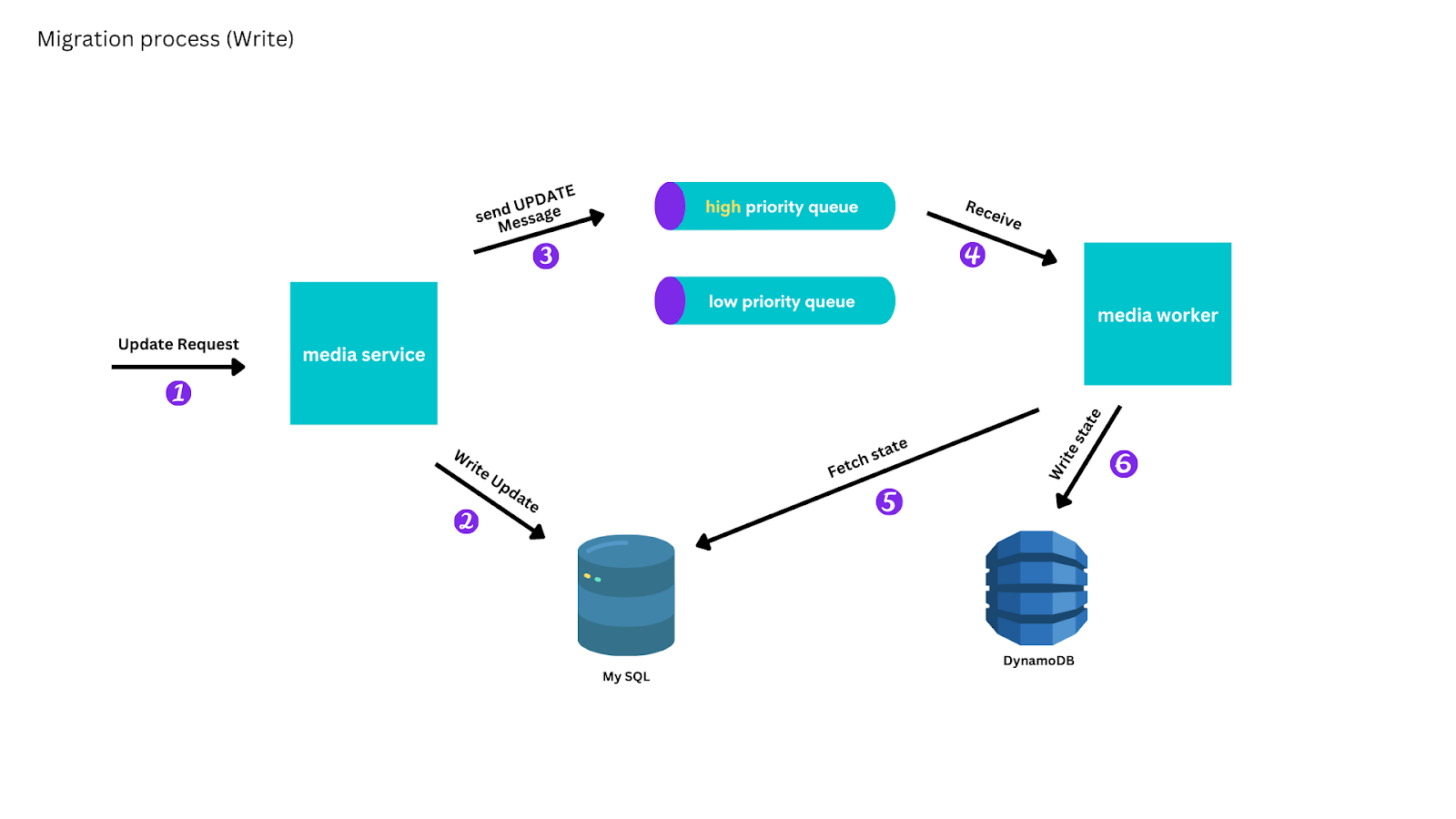
We avoided the difficulty of producing an ordered log — or writing a custom MySQL binlog parser — by enqueuing messages to an AWS SQS queue to identify that a particular media was created, updated, or read, but without containing the content of the update. A worker instance would process these messages to read the current state from the MySQL primary and update DynamoDB if necessary. This allowed the messages to be arbitrarily re-ordered or retried and for message processing to be paused or slowed down.
So that we could serve eventually consistent reads from DynamoDB, we prioritized replication of writes over reads: creates and update messages were placed on a high-priority queue and reads on a low-priority queue. Worker instances read from the high-priority queue until it was exhausted, after which they read from the low-priority queue.
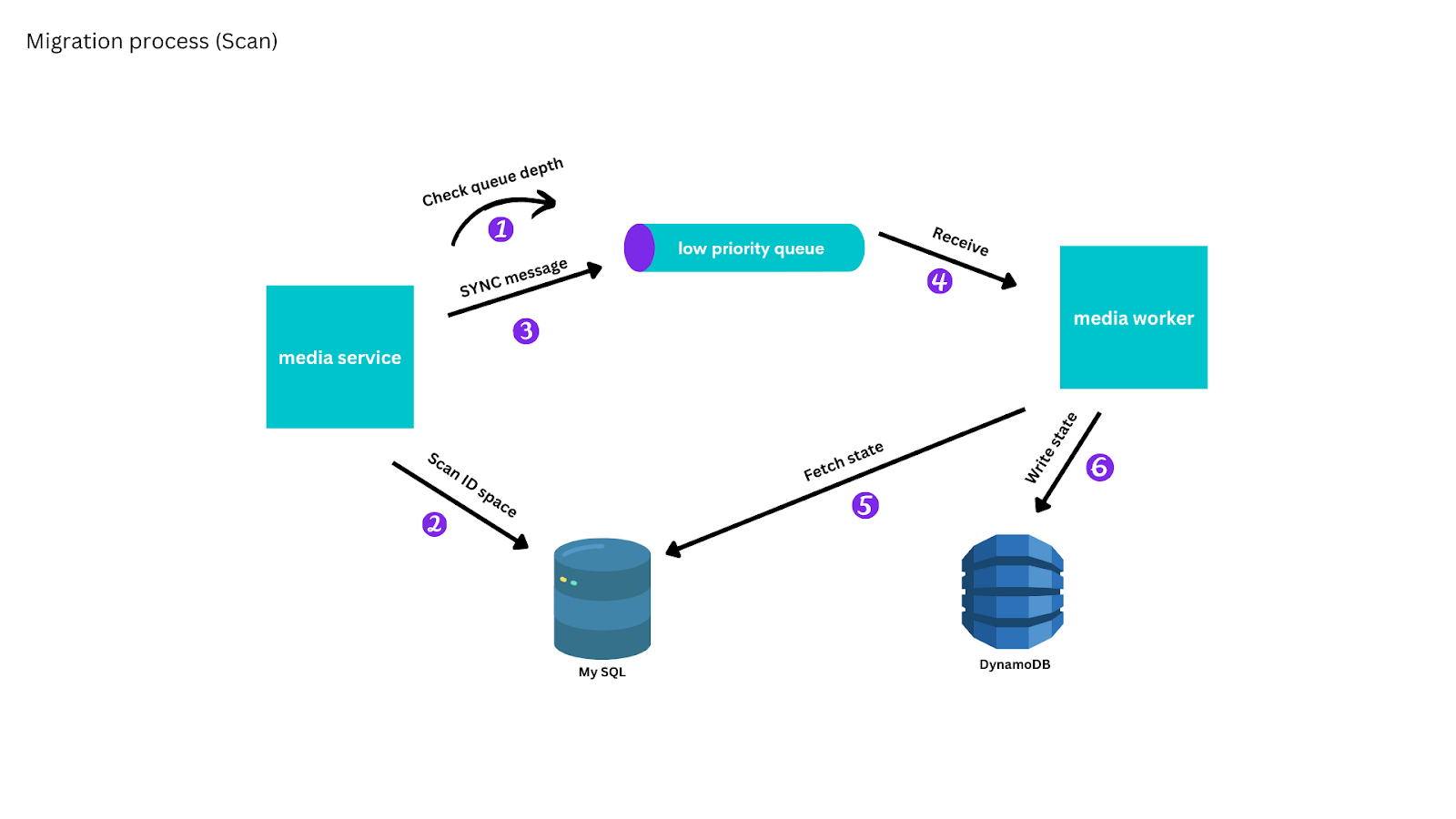
To migrate the remaining media, we implemented a scanning process, which, in line with the access pattern of media, scanned through all media, beginning with the most recently created, and placed a message on the low-priority queue to replicate the media to DynamoDB. We used backpressure so that the synchronization process only advanced while the low-priority queue was approximately empty.
Testing in production
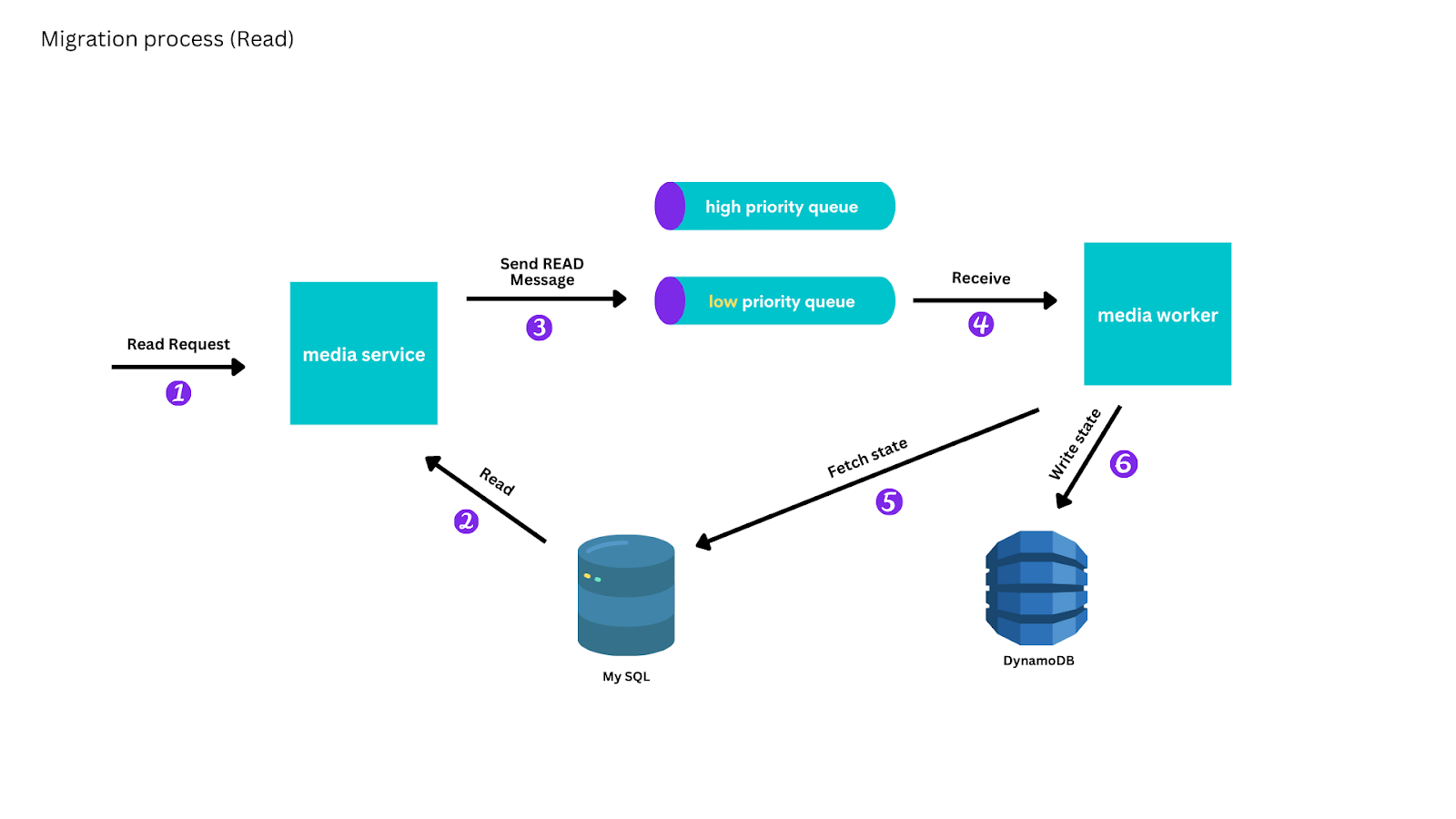
Before we began serving eventually consistent reads exclusively from DynamoDB, we implemented a dual read and comparison process to test our replication process, which compared results from MySQL with the new DynamoDB media service implementation. After resolving the bugs we identified in the replication process, we began serving eventually consistent reads of individual media from DynamoDB, with a fallback to MySQL for the few media which hadn't replicated yet.
Because we were replicating media individually, read requests that didn't identify media by ID, such as finding all media owned by a user, couldn't be served until all media had replicated into DynamoDB. After the scan process completed, we took the same approach of reading from both datastores until we were serving all eventually consistent reads from DynamoDB.
Zero downtime cut-over and fast rollback strategy
Switching all writes to DynamoDB was the riskiest part of the process. It required running new service code to handle create and update requests, which included using transactional and conditional writes to guarantee the same contracts as the previous implementation. To mitigate this risk, we:
- Migrated the existing integration tests for media update requests to test against both migrated media and media created directly on DynamoDB.
- Migrated the remainder of the integration tests to run against the DynamoDB service implementation, running these tests alongside the MySQL implementation tests.
- Tested the new implementation in our local development environment.
- Tested the new implementation using our end-to-end test suite.
- Wrote a run book for the cutover, using our flag system to allow us to switch reads back to MySQL within seconds if required.
- Rehearsed the run book as we rolled out the change through our development and staging environments.
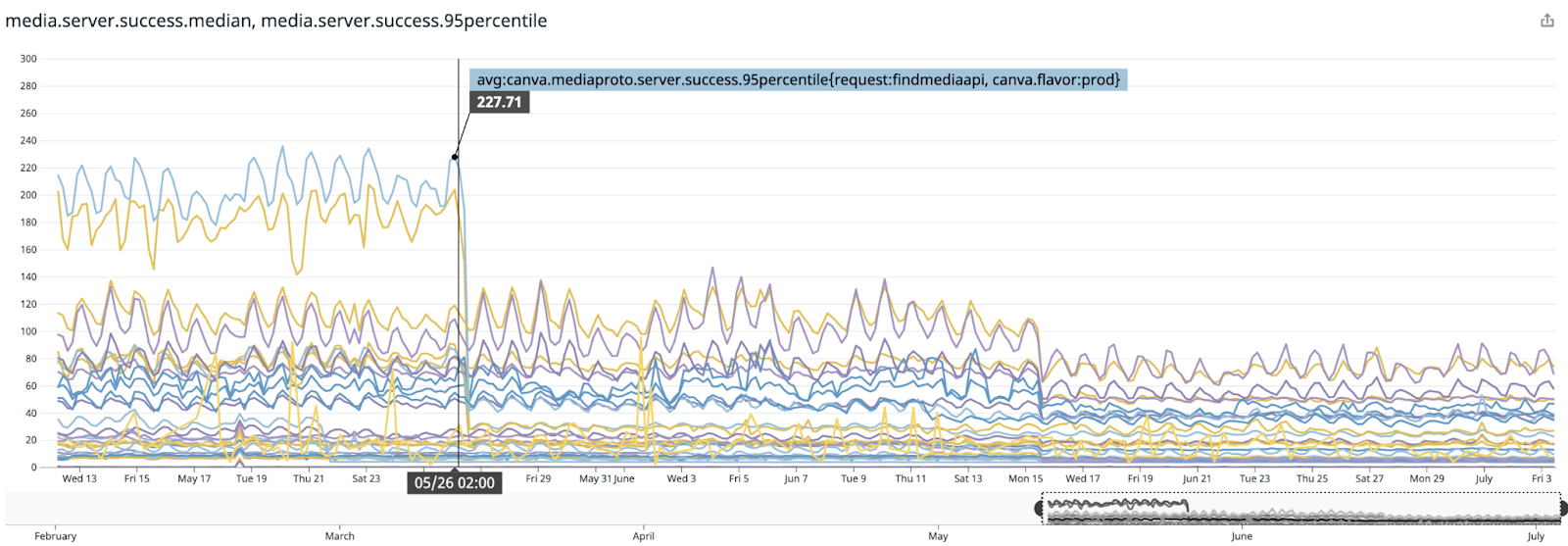
Our cutover in production was seamless, with no downtime or errors, and significant improvements to media service latency, as shown in the following diagram.
Lessons learned
We learned the following lessons in the migration process:
- Be lazy. Understand your access patterns, and migrate commonly accessed data first if you can.
- Do it live. Gather as much information upfront as possible by migrating live, identifying bugs early, and learning to use and run the technology.
- Test in production. The data in production is always more interesting than in test environments, so introduce checks in production where you can.
Was DynamoDB the right choice?
Canva's monthly active users have more than tripled since this migration, and DynamoDB has been rock solid, autoscaling as we've grown and costing us less than the AWS RDS clusters it replaced. In doing this migration we sacrificed some conveniences: schema changes and backfills now require writing and rigorously testing parallel scan(opens in a new tab or window) migration code, and we lost the ability to run ad-hoc SQL queries on a MySQL replica, however we're now serving this need with CDC to our data warehouse. Like many others using DynamoDB, we needed composite global secondary indexes(opens in a new tab or window) to support our existing access patterns, which surprisingly, still need to be created manually by concatenating attributes together. Thankfully at this stage of Canva's growth the structure of core media metadata is relatively stable and new access patterns are rare.
If we were facing the same problem today, we'd once again strongly consider mature hosted "NewSQL" products such as Spanner(opens in a new tab or window) or CockroachDB(opens in a new tab or window).
Canva's media service now stores more than 25 billion user-uploaded media, with another 50 million uploaded daily.
Acknowledgements
A huge thanks to Canva's Media Platform group and our team that made this possible, including Jacky Chen(opens in a new tab or window), Matt Turner(opens in a new tab or window), Vadim Kazakov, Ranie Ramiso(opens in a new tab or window), Luke Lee(opens in a new tab or window), Nik Youdale(opens in a new tab or window) and Brendan Humphreys(opens in a new tab or window).
Interested in scaling Canva's media needs? Join Us!(opens in a new tab or window)