Performance
Canva's compute backend
Developing the Compute Service, aimed at the increasing processing burden of password hashing and the signing of private CDN URLs.
Originally published by Sam Killin(opens in a new tab or window) at product.canva.com(opens in a new tab or window) on September 15, 2015.
A great engineer once told me that it doesn't matter how big your organisation is, you'll always experience growing pains. Canva is far from immune to these pains, and we're constantly reevaluating our infrastructure to ensure that systems designed for Canva of old are still up to scratch for Canva of the present, and will be in good stead to support the Canva of the future.
My first task as the newest, most starry-eyed member of Canva's engineering team was to develop a new backend system, the Compute Service, aimed at tackling one such growing pain: the increasing processing burden of password hashing and the signing of private CDN URLs on our various backend services.
Previously, these CPU intensive hashing and signing functions were tightly coupled to the systems requiring this functionality, giving us no ability to deploy and scale infrastructure focussed on tackling this very particular type of high CPU load separate from the infrastructure requiring it. It was an all or nothing, scale up all our services, or fall behind.
Wait, so what does it do?
The Compute Service performs two tasks.
Firstly, it hashes passwords with the BCrypt(opens in a new tab or window) encryption utility. BCrypt wraps Blowfish, an (intentionally) CPU and time intensive hashing function.
Secondly, it signs temporary URLs that reference private media. We heavily leverage CDN services to efficiently distribute media to our users. In the case of private media, (eg. images uploaded into a user's private image library), we craft and sign special URLs that include an expiration time, after which our CDN provider will not serve any content on that URL. We do this as to ensure we don't have references to private media floating around the internet indefinitely. URLs are signed with a SHA1 hash, which is an order of magnitude less time and CPU intensive to calculate than as is with Blowfish, however we sign an awful lot of these URLs.
It should be noted that the Compute Service is designed to handle CPU demanding functions that are synchronous, or inlined into a single request. For other computationally demanding tasks, such as the export of Canva designs, we place that work on a queue for asynchronous processing and result retrieval at a point in the future. For tasks such as hashing a password during a new user signup, this sort of asynchronous processing is not available to us.
So how'd you do it
The Compute Service is comprised of a cluster of new Amazon EC2 instances, fronted by an Amazon Elastic Load Balancer. These instances serve three main RPCs: one for hashing a password, one for checking a password, and one for computing signed URLs for a batch of private media.
The end goal
We had three goals for the Compute Service:
- Graceful failure: In the event of the Compute Service becoming unavailable, we wanted the rest of our systems to remain as functional as possible, albeit degraded.
- The right tool for the right job: The Compute Service performs a very particular set of tasks that are CPU intensive, rather than being memory or I/O bound. As this service would run as its own dedicated autoscaling group, separate from the five other autoscaling groups that run the rest of Canva's backend services, we had the opportunity to choose an EC2 instance type specifically tailored for these kinds of tasks.
- #cloud: We wanted to be able to raise and lower the capacity of the Compute Service independently from the needs of the rest of our backend services.
We have also recently released features as part of Canva for Work, such as Photo Folders, that require efficient signing of (potentially large) batches of private media URLs. We wanted to leverage the inherent parallelizability of these batch signing tasks by distributing them across the multiple cores of each instance with the goal of reducing the average latency of these requests.
Microservices
The design for the Compute Service essentially boils down to that as described by the Microservice Architecture pattern(opens in a new tab or window). Microservice Architectures, as opposed to Monolithic Architectures, are those where functionally distinct software components are also deployed on separate machines or clusters. Communication between these Microservices is generally over a RESTful HTTP API or some form of RPC, allowing for individual components to be written in different languages, and have different deployment cycles, as well as the advantages listed above.
The right tool for the job
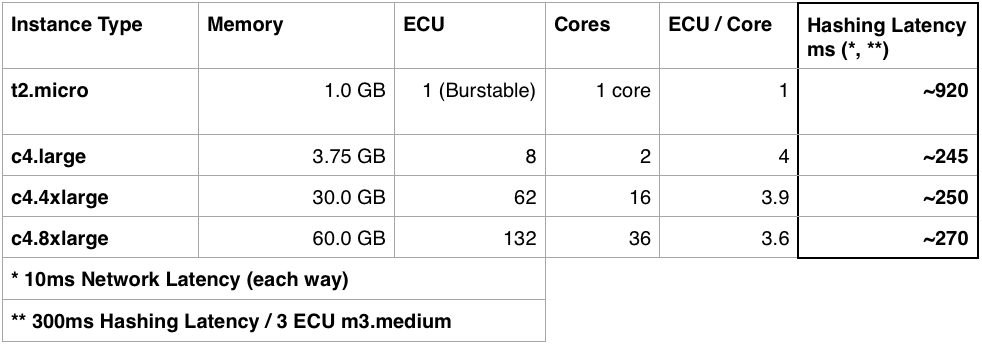
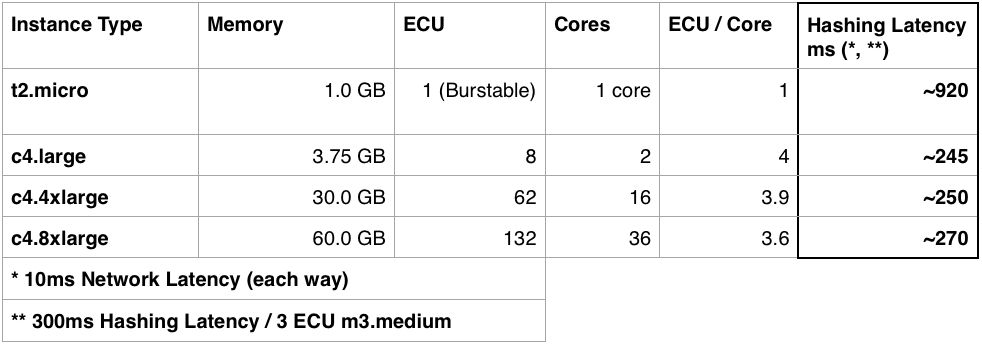
It takes a cursory glance at www.ec2instances.info(opens in a new tab or window) to see that the modern day engineer is blessed with a lot of choices when it comes to Amazon EC2 instance types. For the Compute Service, we narrowed down our choices to the t2.micro type and the c4.8xlarge type. The t2.micro is Amazon's most underpowered, but also cheapest instance type. We were curious about how well an army of t2.micro instances might perform, and how cost effective it would be. As a point of comparison, we compared against the performance of a behemoth c4.8xlarge instance, weighing in at 132 ECUs across 36 cores. For reference, ECU refers to equivalent compute unit, Amazon's standardised measure of clock speed across all cores of an instance. The c4.8xlarge comes from Amazon's "compute" category of instances, and is the beefiest therein. Somewhat unsurprisingly, engineering prevails, and we settled on neither of the two, and instead found a compromise with the c4.large type.
We ruled out the t2.micro by examining password hashing performance. As you are unable to distribute a single password hashing task across multiple instances, each password will end up on a single t2.micro core, each of which is around four times slower than each core on Amazon's "compute" type instances. Using t2.micros would have given us finer grain control over machine utilisation, but at the cost of request latency for password related operations. To compare the different instance types, we measured the performance on an m3.medium, and assumed the latency of the password hashing task would scale inversely with the number of ECUs per core on each instance type:
We then compared the batch URL signing performance across the "compute" instance types. Again, we estimated the performance on each instance type by assuming that the latency of signing a batch of URLs would scale inversely with the number of ECUs per core and the number of cores:
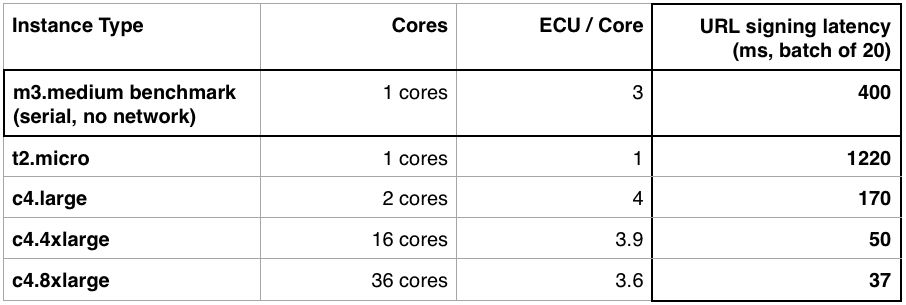
The latency of URL signing is significantly reduced when undertaken by the "compute" type machines, as compared to the m3.medium machines (that handle the vast majority of Canva's general purpose load). This is especially apparent with the larger types which provide a greater number of cores per machine, across which the batch signing tasks are distributed. It should be noted that Amazon's pricing scheme for these instances is linearly proportional to the ECU of each type. This means that deploying eight c4.large instances (at 8 ECU each) delivers approximately the same raw computational power, at approximately the same price, as a single c4.4xlarge at 62 ECU, albeit with a different hierarchy of machines and cores.
Examining existing traffic, we estimated that we only require approximately 6 ECU's of peak compute capacity to handle URL signing and password hashing tasks in Canva's immediate future. As such, we settled on deploying a single c4.large instance, which provides 8 ECU's of capacity. We underestimated this (within an order of magnitude), and currently run between two and four c4.large instances to handle compute tasks. Several assumptions in our modelling contributed to this misestimation. For example, we made the assumption that computational tasks could be perfectly distributed across multiple workers, when in fact there are diminishing returns when increasing the parallelism of any system. Errors were also introduced through the estimation of model inputs such as the benchmark time taken to hash passwords and sign private URLs on m3.medium instances. These errors in estimation and assumption compound, adding to the misestimation in overall required capacity. We also based our calculations on historical average hourly throughput at peak times, which is less volatile than our second-to-second throughput. To ensure that we always have enough capacity to handle any spikes in this instantaneous peak demand (with some capacity to spare) we like to have auto-scaling policies that err on the side of over-deploying rather than under-deploying instances.
As we continue to grow, we look forward to exploring the use of larger compute type instances. The various compute instance types scale up linearly across capacity and price, however the larger types offer more cores per machine. This hints at opportunities to further reduce latency through increased parallelization of each request once we grow into the shoes of those beefier instance types.
Results
We undertook load testing of our folder service (which delegates a large amount of computational work to the Compute Service) with the Compute Service initially disabled and then enabled with a single instance in order to understand the effectiveness of delegating those tasks to separate instances. The following graph demonstrates two bursts of traffic to the folder service, first with the Compute Service disabled, and second with the Compute Service enabled. As can be seen, the request volume is approximately equal over the same approximate time period in both tests.
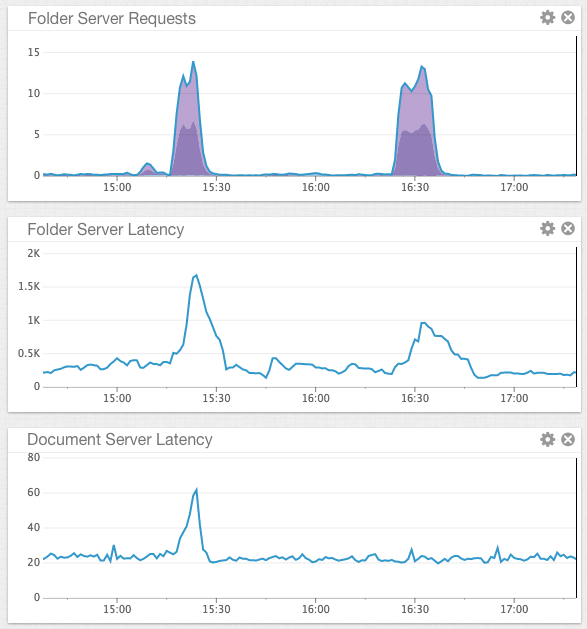
Examining the folder service latency (the middle graph), we can see that enabling the Compute Service successfully reduces latency on folder requests by approximately half. This correlates with the two-fold parallelisation provided by the c4.large instances (with a little bit of inefficiency a la Ahmdal's law(opens in a new tab or window)), as compared with the single core m3.medium.
Before delving into the document service latency (the last graph) I should explain that document service is largely independent of the Compute Service. It is, however, served from the same instances that manage the folder service. With that in mind, you may notice the point of interest. With CDN URLs being signed locally, the burst of load on the folder service propagated across multiple services, even if those services are not dependant on those functions delegated to the Compute Service. This reduced coupling between services gives us greater overall systematic resiliency across Canva's backend.