Machine Learning
Machine learning hyperparameter optimization with Argo
How the hyperparameters of our machine learning models are tuned at Canva.
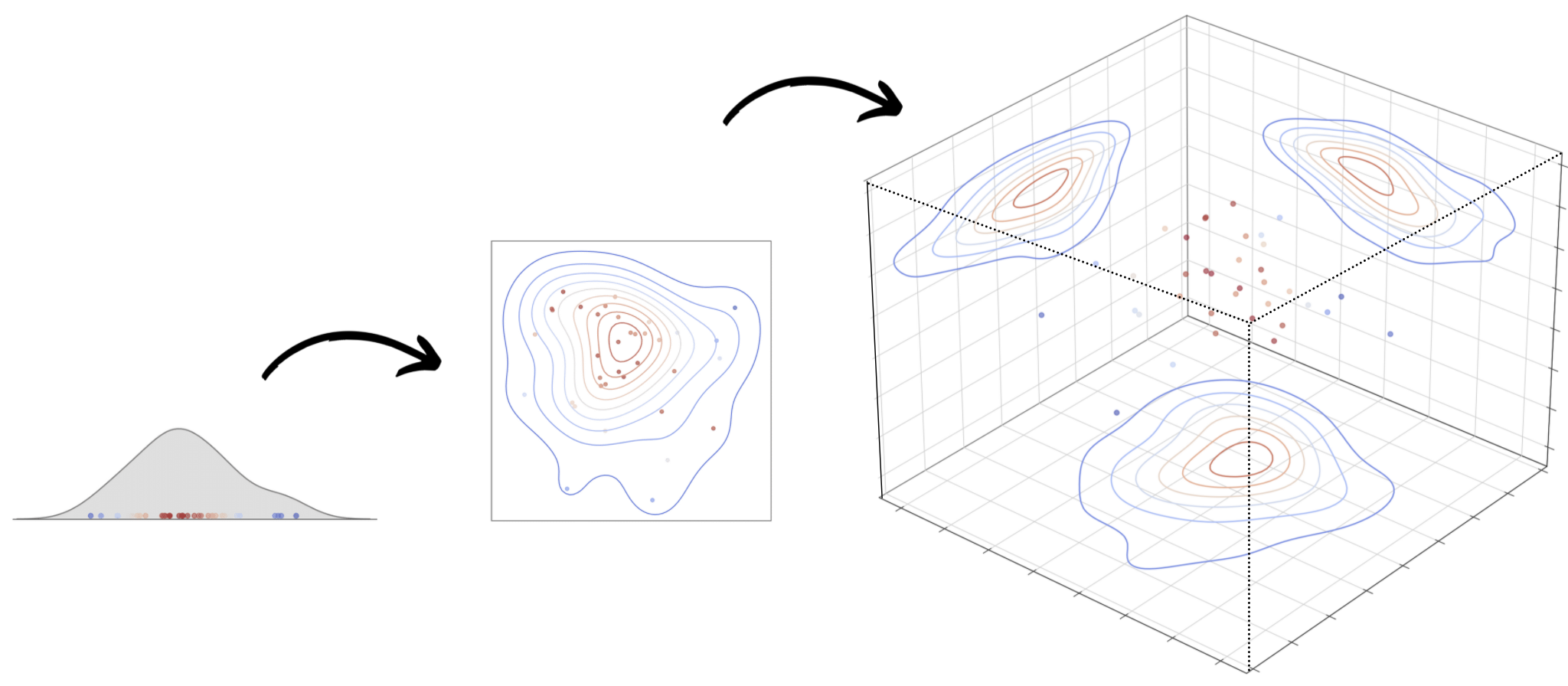
Canva uses a variety of machine learning (ML) models, such as recommender systems, information retrieval, attribution models, and natural language processing for various applications. A typical problem is the amount of time and engineering effort in choosing a set of optimal hyperparameters and configurations used to optimize a learning algorithm's performance.
Hyperparameters(opens in a new tab or window) are parameters set before a model's learning procedure begins. Hyperparameters, such as the learning rate and batch sizes, control the learning process and affect the predictive performance. Some hyperparameters might also have a significant impact on model size, inference throughput, latency, or other considerations.
The number of hyperparameters in a model and their characteristics form a search space of possible combinations to optimize. In the same way that a rectangle's area is quadratic to its width, when experimenting with two continuous hyperparameters the permissible search space is the area constructed by all combinations of the two hyperparameters. Every hyperparameter introduced grows the search space exponentially, leading to a combinatorial explosion of the search space, as shown below.
The intense effort to optimize hyperparameters is typical of modern
natural language processing applications that involve fine-tuning large
pre-trained language models, which take a few days to finish training.
In fact, training a model, such as GPT-3, from scratch takes
hundreds of GPU years and millions of
dollars(opens in a new tab or window). Simpler models, such as XGBoost, still have a
myriad of hyperparameters(opens in a new tab or window), each with
nuanced effects. For example, increasing max_depth increases memory
footprint, while tuning the tree construction implementation has a
significant effect on latency and throughput.
A distributed hyperparameter optimization solution is the answer to the general trend of larger models trained on larger data. It also fits in well with how Canva operates machine learning models: moving and iterating fast in an environment of compounding scale.
Machine learning engineers always have the opportunity to perform their custom hyperparameter optimization on top of vertically scaled model trainers. Yet, at the limits of vertical scaling, distributed hyperparameter optimization is the process of spreading the individual model trainers across different pods and hosts.
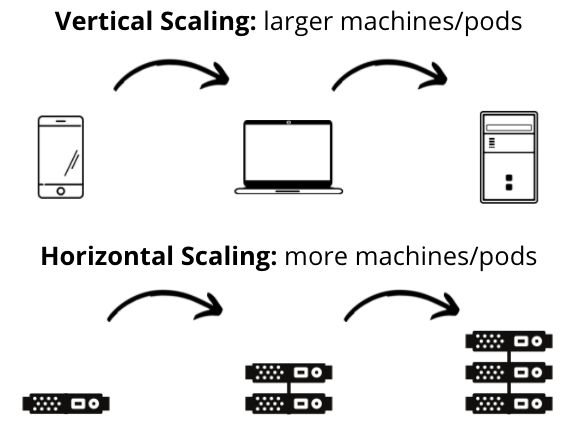
Resource constraints are a massive challenge when relying solely on vertical scaling. Despite the ever-increasing instance sizes available on modern cloud platforms, it's difficult to scale model training time linearly across multiple accelerators (GPUs). Moreover, any hyperparameter optimization procedure on top of an existing model trainer that efficiently uses all the processes involves either trading off the number of processes a trainer can use when tuning in parallel or running all the experiments in sequence
This post shows how Canva solves these challenges.
Hyperparameter Optimization with Argo
Argo Workflows(opens in a new tab or window) is a Kubernetes-native workflow orchestration framework that takes care of pod execution, management, and other common needs when running ephemeral jobs on Kubernetes(opens in a new tab or window). Argo's extendability and ability to provide a single deployable unit were some of the benefits that led us to pick Argo over other workflow orchestration frameworks. At Canva, we leverage it to schedule and run all model trainers on our Kubernetes clusters.
Distributed hyperparameter optimization's complexity can be separated into computational and algorithmic complexity. We use Argo workflows to support and orchestrate the computational requirements of these hyperparameter optimization jobs. The algorithmic problem is delegated to one of many available open-source frameworks (we use Optuna(opens in a new tab or window) at Canva).
Argo and Alternatives
It's desirable to use the exact model trainer framework and apply it to hyperparameter optimization jobs because of the many choices of existing custom tooling and integrations. Moreover, this enables engineers to treat hyperparameter optimization as a model training procedure. Doing so allows the learning of the model's architecture along with the usual model parameters without coupling the optimization and training concerns.
There are alternatives, of course.
Over the last few years, there's been an explosion of open-source and proprietary libraries and platforms attempting to do the full scope of model training, tuning, and even serving. Concentrating on the latest open-source solutions, a large number of libraries, including Optuna, have tooling for running hyperparameter optimization jobs on Kubernetes.
We only use the algorithms of third-party optimization frameworks due to the cost of introducing new platform technology. It's so important to choose technology carefully, as opposed to installing the newest Kubernetes framework. Any new technology introduces costs, such as maintenance, tooling, and training time. This principle is also why each item in our technology stack has minimal overlap with each other.
Argo gives us operational support, monitoring, scalability, and custom tooling from our machine learning trainers. It also doesn't compromise the benefits of using or extending the best optimization libraries available. We can maintain the option to replace the optimization algorithms and libraries depending on industry tides or use-case nuances. We no longer need to worry about how the pods are run.
Defining the Hyperparameter Optimization Workflow
There are many ways of defining the dataflow in a hyperparameter optimization workflow. One option is to define a temporary (but relatively long-living) optimization service that computes the next hyperparameter experiment in which a model trainer consumes.
Another is to treat hyperparameter optimization as a sequence of map-reduce operations(opens in a new tab or window). Although this has downsides, such as requiring all parallel model trainers to finish before running the next batch, it's far easier to extend and reason about within a workflow.
The map-reduce approach requires two kinds of application containers with differing responsibilities:
- Optimizer: A single container generating the next batch of hyperparameters to explore based on all previous hyperparameters and model evaluation results.
- Model Trainers: A batch of model trainer containers that accepts hyperparameter values and returns pre-defined evaluation metrics.
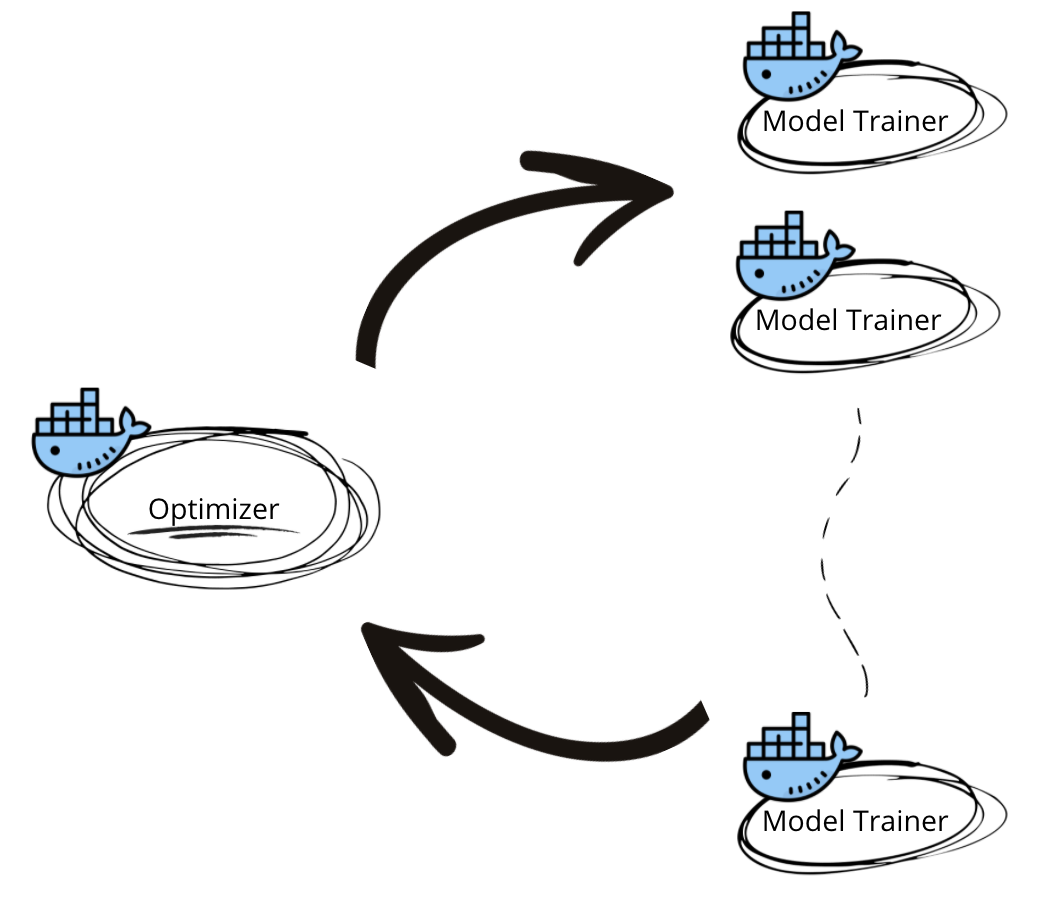
The interaction between the optimization and model training containers is essential. The optimization container first generates the next batch of hyperparameters to explore within a single optimization iteration. The workflow then fans out the batch of hyperparameters to each model trainer running in parallel. The bulk of time spent within each iteration is then in the model training itself. When the model trainers finish they return their respective metrics. Argo then aggregates the values into the next instantiation, beginning the next iteration if the termination criteria is not satisfied.
One challenge of defining a hyperparameter optimization workflow like this is the handling of optimization state. Each optimization container must have access to all preceding hyperparameter values and their results. A solution is to persist the intermediate results into a database. This would be ideal if many model trainers share the same optimizers. We found that passing the optimization state explicitly through the workflow itself is more desirable because it isolates each hyperparameter optimization job and mitigates the need to maintain a long-living persistence mechanism.
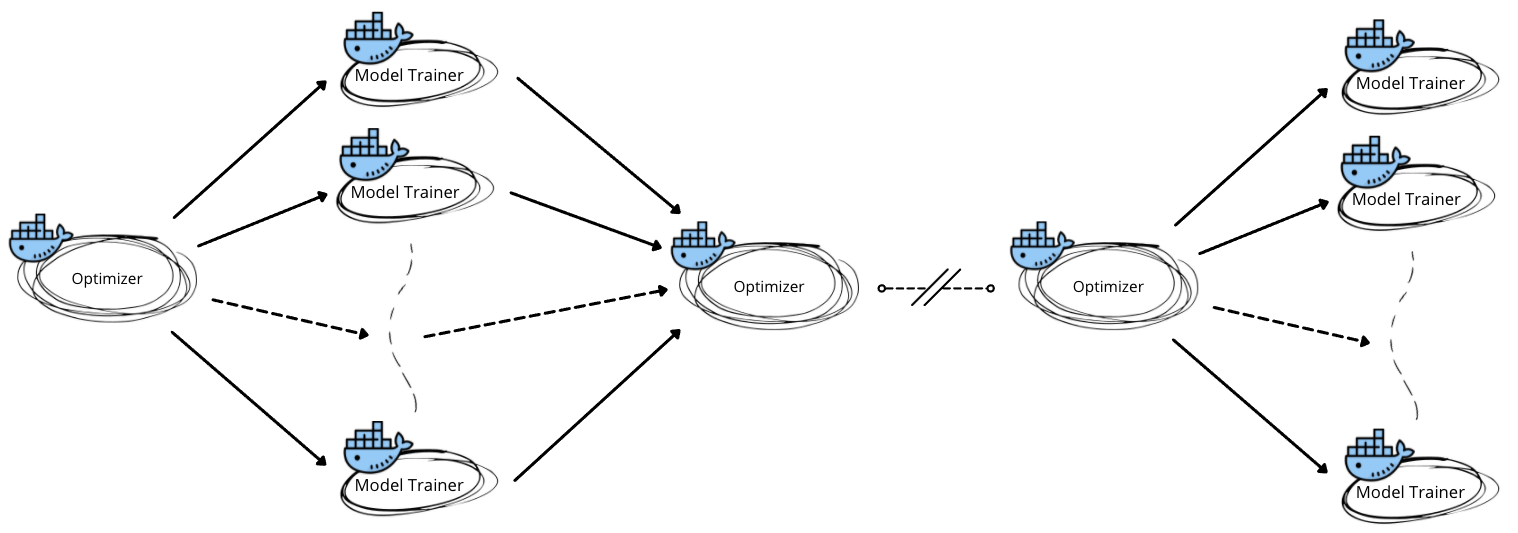
After solving the orchestration challenges, the optimizer itself wraps open-source optimization libraries, such as Optuna. This gave us an average speedup of at least five times over our previous process. We went from over a week to optimize down to a little over a day.
Defining the Optimizer
A separate optimization container means that the model trainers do not need to know about hyperparameter optimization. Their concerns are delineated with minimal coupling. The optimization is thus free to use any heuristic or algorithm it chooses, such as Randomized Search.
We found that it's far easier to refit the entire optimization model after each batch instead of doing a partial fit. This has only a marginal effect on the optimization time. It also avoids the need to maintain custom optimization state representations that depend on the algorithm.
Argo CLI and UI enable machine learning engineers to specify their desired search spaces and hyperparameter configurations at run-time. The search space gets supplied as a set of hyperparameters to search through and their probability distributions. These distributions (such as uniform, discrete-uniform, log-uniform, or categorical) are a form of prior knowledge. The prior knowledge enriches the hyperparameter optimization process so that the optimizer can better navigate the search space.
Machine learning engineers can also select the desired optimization algorithm, control the degree of parallelism, the number of iterations, and others as run-time parameters. Lastly, by passing the optimization state through the workflow explicitly, engineers can also create new hyperparameter optimization jobs from the state of a previous one. This effectively enables engineers to warm-start the optimization and iteratively relax or constrain the search space across multiple jobs.
Bayesian Model-based Hyperparameter Optimization
At Canva, we leverage Bayesian optimization(opens in a new tab or window) methods to efficiently navigate large hyperparameter search spaces. These methods are sample-efficient because they select the next hyperparameter (the vertical line in the graph below) which is likely to yield the largest improvement, and thus reduce the number of times an objective function needs to be evaluated in order to reach a well-optimized point. This characteristic is especially important for ML.
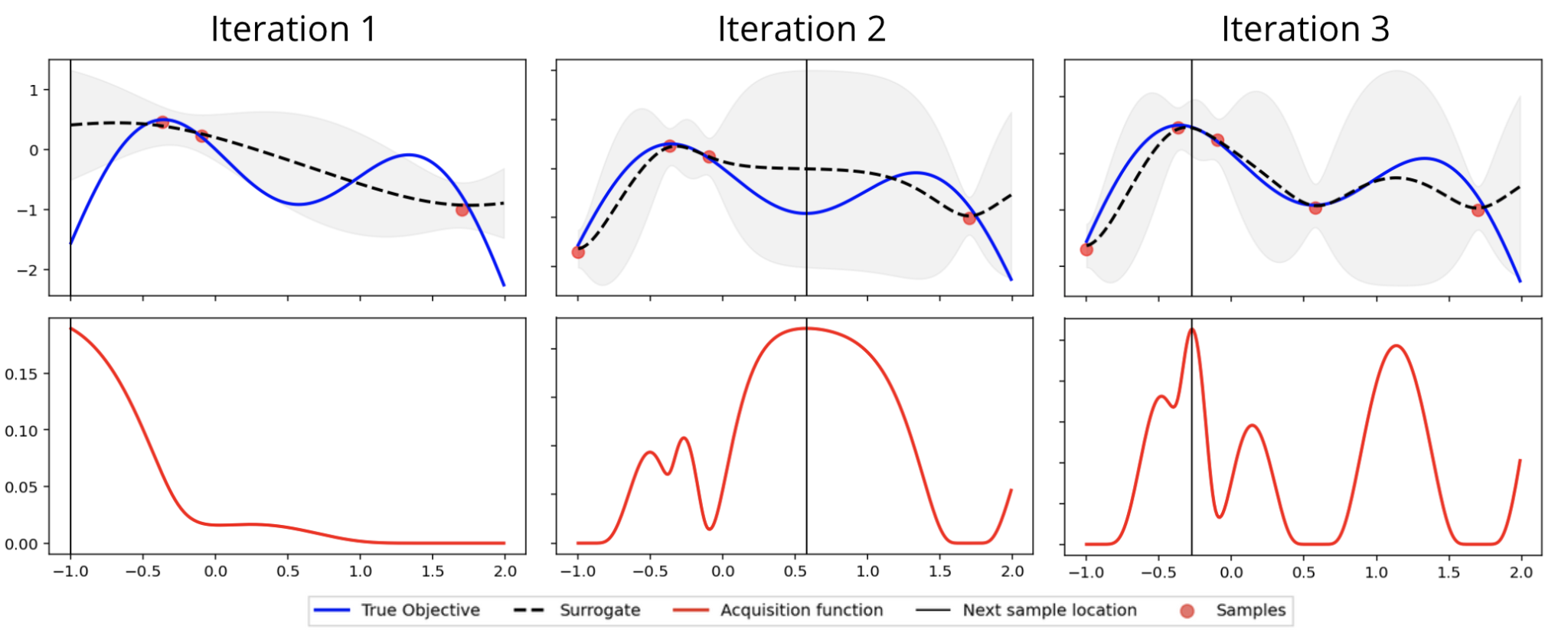
By building a probabilistic "surrogate" model from hyperparameter values and previous model evaluation results, Bayesian optimization methods balance exploring regions in the search space with high uncertainty while exploiting regions around the best-known values of the probabilistic model. As a form of sequential model-based optimization(opens in a new tab or window) (SMBO), Bayesian optimization is most efficient when the evaluation of the expensive objective function is performed sequentially.
One of the problems with using pure SMBO in batch with high degrees of concurrency is that the batch of suggested hyperparameters tends to clump together(opens in a new tab or window), limiting the effectiveness of distributed hyperparameter optimization and wasting compute by evaluating a small concentrated subset of the search space.
To provide a solution generic to the optimizer for this problem, we use a Constant Liar (CL) heuristic(opens in a new tab or window) when sampling within a batch. This strategy generates temporarily "fake" objective function values when sampling sequentially for each batch. By modifying the optimism and pessimism of the optimizer via the generated objective values, we control the degree of exploration within a batch of concurrent ML experiments. Finally, since exploration is almost certainly needed at the start of any hyperparameter optimization job, we force the optimizer to generate random samples in the first batch.
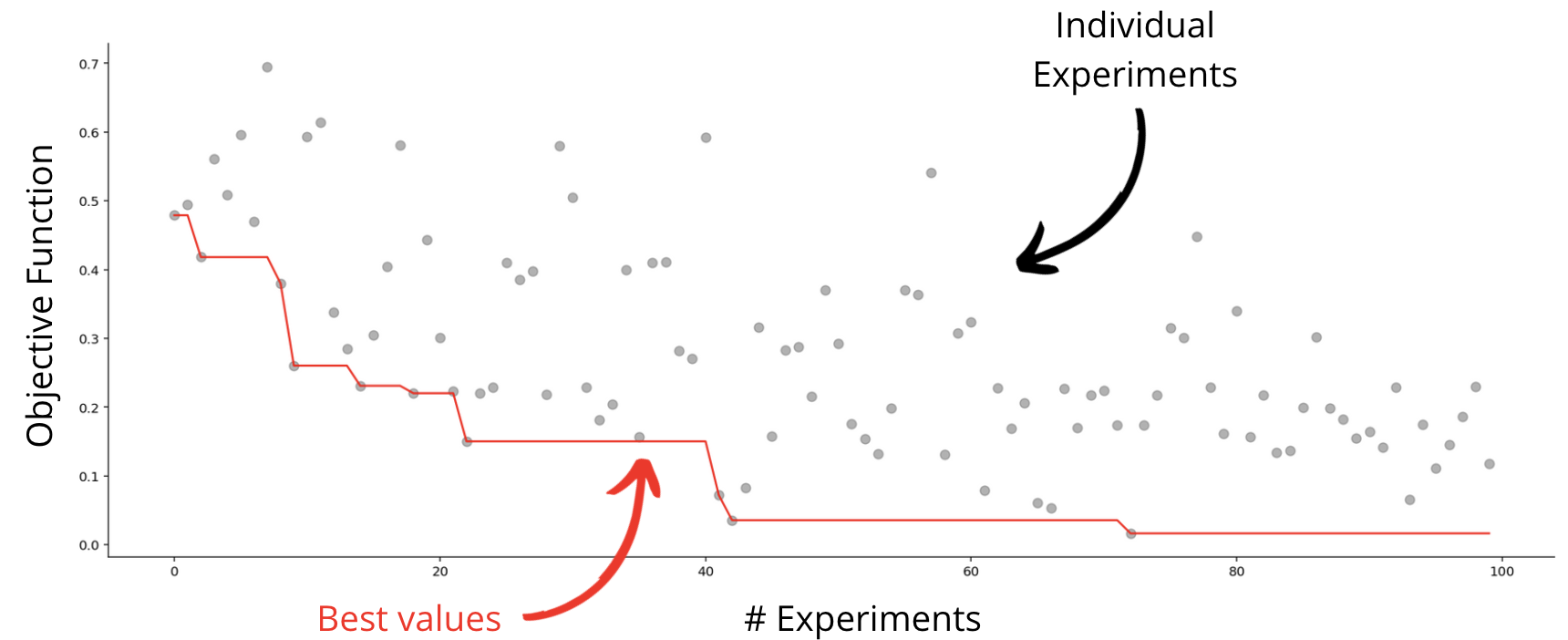
Conclusion
Distributed hyperparameter optimization is an unavoidable problem when iterating on ML models at scale. We've accelerated the experimentation and tuning of ML models in a manner that's enabled both the computational and algorithmic components to evolve individually. In practice, this has decreased the optimization time of some models from a week to a little over a day. By iterating on ML use-cases faster, we hope to empower our users' experience to be more magical and delightful.
Acknowledgements
Special thanks to Jonathan Belotti(opens in a new tab or window), Sachin Abeywardana(opens in a new tab or window), and Vika Tskhay(opens in a new tab or window) for their help and guidance. Huge thanks to Grant Noble(opens in a new tab or window) for editing and improving the post.
Interested in advancing our machine learning infrastructure? Join us(opens in a new tab or window)!


