Microservices
Lessons learnt from building reactive microservices for Canva Live
Behind the scenes on our mission to drive the next era of presentation software.

Originally published by Ashwanth Fernando(opens in a new tab or window) at medium.com/canva(opens in a new tab or window) on October 12, 2020.
Presentations are one of the most popular formats on Canva, with everyone from small businesses, to students and professionals creating stunning slide decks — averaging up to 4 new designs per second. But to truly drive the next era of presentation software, we're empowering our community with live, interactive features. In this blog, Canva Engineer Ashwanth Fernando shares how the team launched a real-time experience through a hybrid-streaming backend solution to power the Canva Live presentation feature.
With over 4 million people creating a new presentation on Canva each month, it's no surprise this doctype consistently ranks as one of the fastest growing on our platform. But other than delighting our community with professional-looking presentation templates, we're always on the lookout for new ways to demonstrate the magic of Canva.
Throughout our research, it was clear that people invest time into creating a beautiful slideshow for one simple reason: every presenter wants maximum engagement. That's why we're seeing less text, and more photos, illustrations, and animations.
To take engagement to the next level, we challenged ourselves to introduce real-time interactions, that allow every presenter to communicate with their audience easily, effectively and instantaneously. This is how Canva Live for Presentations came to be.
What's Canva Live?
Canva Live is a patent-pending presentation feature that lets audiences ask live questions via a unique url and passcode on their mobile device. Submitted questions can then be read by presenters in a digestible interface, to support fluid audience interaction. For a visual demonstration of this, you can view the below video:
As demonstrated, the audience's questions appear in real-time on the presenter's screen, without the page having to refresh. The traditional way to achieve this would be to poll the server at regular intervals — but the overhead of establishing a Secure Sockets Layer (SSL) connection for every poll would cause inefficiencies, potentially impacting reliability and scalability.
Hence, a near real-time (NRT) experience is essential for Canva Live, while offering maximum reliability, resilience and efficiency. We achieved this with a novel approach to reactive microservices.
Creating a Real-Time Experience through a Hybrid-Streaming Backend Solution
Canva Live works over a hybrid streaming system. We transmit questions, question deletions, and audience count updates — from the Remote Procedure Call Servers (RPC) to the presenter UI — via a WebSockets channel. As WebSockets constantly remain open, this means the server and client can communicate at any time, making it the ideal choice for displaying real-time updates.
As the number of connections between audience members and the RPC Fleet must scale in line with audience participants, we use more traditional request/response APIs for this. These connections are only required to transfer data at specific moments (eg. when a member submits a question), and multiple instances of an always-open WebSocket channel would use unnecessary compute resources.
For clarity, we have created a diagram of the technology stack below (Fig. 1). The presenter and audience connect to a gateway cluster of servers, which manages all ingress traffic to our microservice RPC backend fleet. The gateway manages factors such as authentication, security, request context, connection pooling and rate limiting to the backend RPCs. The Canva Live RPC fleet is an auto-scaling group of compute nodes, which in turn talk to a Redis backend (AWS Elasticache with cluster mode enabled).
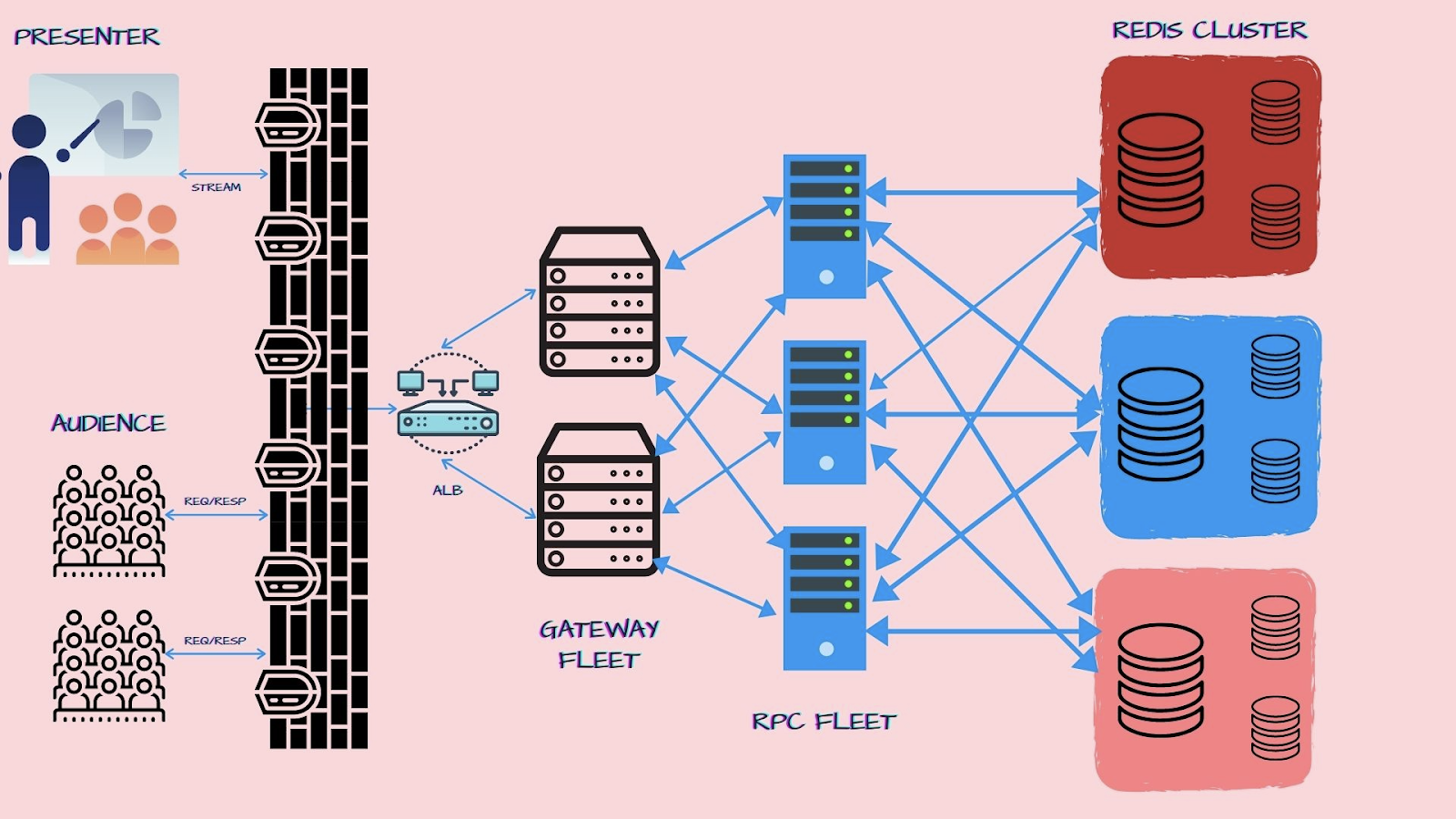
Though the diagram looks very similar to a traditional n-tier deployment topology, we found an incredible variety of differences when building scalable streaming services. Below, we explain how potential landmines were avoided, and the valuable lessons we learnt in building Canva Live.
Consider Building For Scale From Day 1
As software engineers, we all love the ability to build incrementally, then increase industrial strength and robustness based on traffic — especially when building a new product. For Canva Live, we had to prepare for wide scale usage from day one, with its start button being baked-in to one of our most popular pages.
Redis Scalability
Our Redis database is deployed with cluster mode enabled and has a number of shards with a primary master and replica. The replicas are eventually consistent with the data in the primary nodes, and can quickly be relied on if primary nodes are down. The client side is topology-aware at all times. It knows which node is a newly elected primary and can start re-routing reads/writes when the topology changes. Adding a new shard to the cluster and scaling out storage is easy within the click of a few buttons/commands as shown here(opens in a new tab or window).
RPC scalability
At our RPC tier, our compute nodes are bound to a scaling group that auto-scales based on CPU/memory usage.
Gateway/Edge API layer scalability
Our gateway tier sits at the edge of our data-center. It is the first component to intercept north-south traffic, and multiplexes many client websocket connections, into 1 connection to each RPC compute node. This helps scalability, as the direct mapping of client connections to compute nodes creates a linear growth on socket descriptors at the RPC compute node (which is a finite resource) The flip side of multiplexing is that the gateway tier cannot use Amazon Load Balancer (ALB) to talk to RPCs, as it has no knowledge of how many virtual connections are being serviced over a physical connection. As a result the ALB could make uninformed choices, when load balancing websocket connections over the RPC fleet. Hence, our gateway tier uses service discovery, to bypass the ALB, and talk directly talk to the RPC nodes.
Choosing The Right Datastore
Choosing the optimal data store is one of the most important yet overlooked aspects of system design. Canva Live had to be scalable from the start, with the system plugging into our high-traffic, existing presentation experience. Defaulting to an RDBMS database that only supports vertical scalability of writes, would make it more difficult to support growth.
To build an end-to-end reactive system, we required a datastore with a reactive client driver to enable end-to-end request processing of the RPC, using reactive APIs. This programming model allows the service to enjoy the full benefits of reactive systems (as outlined in the reactive manifesto(opens in a new tab or window)), prioritizing increased resilience to burst traffic, and increased scalability. We also needed a publish-subscribe (pub/sub) API that implements the reactive streams spec, to help us monitor data from participant events, such as questions and question deletions.
Secondly, our session data is transient with a pre-set invalidation timeout of a few hours. We needed to expire data structures without performing housekeeping tasks in a separate worker process. Due to the temporary lifetime of our data, a file system based on databases would create the overhead of disk accesses. Finally, we have seen phenomenal year-on-year growth in our presentations product, and needed a database to horizontally scale.
We chose Redis as our datastore, as it best met the above requirements.
After analysing the pros and cons between the Redisson and lettuce Java Clients, we opted for the latter. lettuce was better suited, as its commands directly map onto the Redis counterpart.
The lettuce low level java client for Redis provides a PubSub API based on the Reactive Streams, (specifications listed here)(opens in a new tab or window), while Redisson supports all the Redis commands but has its own naming and mapping conventions (available here(opens in a new tab or window).)(opens in a new tab or window).
Redis also supports expiry of items for all data structures. In Redis cluster mode, we have established a topology that lets us scale from day one, without the need for code change. We host the Redis cluster in AWS Elasticache (Cluster Mode enabled) which lets us add a new shard, and rebalance the keys with a few clicks.
Besides all of the above benefits, Redis also doubles up as a data-structures server, and some of these data-structures were suitable candidates for Canva Live out of the box — such as Redis Streams and SortedSets.
It is worth mentioning that user updates could also be propagated to different users by using Kafka and/or SNS+SQS combos . We decided against either of these queuing systems, thanks to the extra data-structures and K-V support offered by Redis.
Consider using Redis Streams for propagating user events across different user sessions
There can be hundreds of question-adding and deletion events in just one Canva Live session. To facilitate this, we use a pub-sub mechanism , via Redis Stream — a log structure that allows clients to query in many different ways. (More on this here(opens in a new tab or window)).
We use Redis Streams to store our participant generated events, creating a new stream for every Canva Live session. The RPC module runs on an AWS EC2 node, and holds the presenter connection. This calls the Redis XRANGE command every second to receive any user events. The first poll in a session requests all user events in the stream, while subsequent polls only ask for events since the last retrieved entry ID.
Though polling is resource inefficient, especially when using a thread per presenter session, it is easily testable, and lends itself to Canva's vigorous unit and integration testing culture. We are now building the ability to block on a stream with an XREAD command while using the lettuce reactive API to flush down the user events to the presenter. This will allow us to build an end-to-end reactive system, which is our north star.
We'll eventually move to a model, where we can listen to multiple streams and then broadcast updates to different presenter view sessions. This will decouple the linear growth of connections from threads.
In our Redis cluster mode topology, streams are distributed based on the hash key, which identifies an active Canva Live Session. As a result, a Canva Live event stream will land on a particular shard and its replicas. This allows the cluster to scale out, as not all shards need to hold an event stream.
It's hard to find an API counterpart like the Redis XREAD command in other database systems. Listening capabilities that span different streams are generally only available to messaging systems like Kafka. It's wonderful to see this out of the box, in an in-memory data-structures server such as Redis, with simple key/value support. AWS Elasticache provides all this goodness without the headaches of administering a multi-master, plus replica Redis cluster.
Minimize Network Traffic By Offloading Querying To The Datastore As Much As Possible
Using a tactic taken straight from the RDMBS handbook, we have minimized network traffic by offloading querying to the datastore.
As mentioned previously, our version 1 implementation used polling between RPC and Redis, to fetch new comments and manage the audience counter. However, repeated calls across several Canva Live presentations can create significant network congestion between the RPC and Redis cluster, meaning it was critical for us to minimize traffic volume.
In the case of the audience counter, we only want to include new, active participants. To do this, we use a Redis SortedSet to register a participant ID, plus the current timestamp. Every time a participant polls again, the timestamp for the participant id is refreshed, by calling the Redis command, ZADD (this adds the participant id along with the current timestamp, which is always sorted).
Then we need to confirm the audience count. We call Redis command ZCOUNT (count the number of items between a range of timestamps), with the current timestamp (T) and T — 10 seconds, to calculate the number of live participants within the last ten seconds. Both commands ZCOUNT and ZADD, have a time complexity of log(N), where N is the total number of items in the SortedSet.
Imagine doing something like this in a file system-based database. Even if the database promised log(N) time complexity, the log(N) is still disk I/O dependent for each operation — which is far more expensive than doing it in-memory.
Redis supports many more data-structures like SortedSet with optimal time complexity out of the box. We recommend using these, rather than resorting to key value storage and performing data filtering and/or manipulation at the RPC layer. The entire list of Redis commands is here https://redis.io/commands(opens in a new tab or window)
Understand the nuances of Redis transactions
The concept of transaction in Redis is very different from its counterpart in traditional RDBMS. A client can submit an operations sequence to a Redis server as a transaction. The Redis server will guarantee the sequence is executed as an atomic unit without changing context to serve other requests, until the transaction is finished. However, unlike an RDBMS, if one of the steps in the sequence fails, Redis will not roll back the entire transaction. The reasoning for this behavior is listed here — https://redis.io/topics/transactions#why-redis-does-not-support-roll-backs(opens in a new tab or window)
Furthermore, a Redis cluster can only support transactions if the sequence of operations works on data structures in the same shard. We take this into account when we design the formulation of the keys hash tag for our data structures. If our data structures need to participate in a transaction, we use use keys that map to the same shard (see here(opens in a new tab or window) https://redis.io/topics/cluster-spec#keys-hash-tags(opens in a new tab or window)), to ensure these data structures live in the same shard.
Ideally we'd like to do transactions across shard boundaries, but this will lead to strategies like two-phase commits, which could compromise the global availability of the Redis cluster (see CAP Theorem(opens in a new tab or window)). Client specified consistency requirements like Dynamo would be more welcome for Redis transactions.
Minimize streaming connections to chatty interactions
It's easy to get carried away and build every API over a streaming connection. However, a full-fledged streaming API demands substantial development effort, and runtime compute resources.
As mentioned previously, we stuck with request and response APIs for the participant-facing Canva Lives features, which has proven to be a good decision. However, a case can be made for use of streaming here, because of the audience counter.
Instead of repeatedly polling Canva every few seconds to inform availability, using a websockets connection can greatly simplify Redis storage by switching from the existing SortedSet to into a simple key/value store for the participant list. This is because we can detect when the client terminates the websockets connection, and use that event to remove the participant from the key value store.
We voted against using participant side WebSockets connections because our first iteration uses one JVM polling thread per streaming session. If we used the same approach for the participant, it could lead to an unbounded number of threads per RPC server, with no smart event handling system in place.
We're in the design stage of replacing the polling model with a system that uses a single thread to retrieve updates across several transaction logs. This will broadcast updates to participants connected to the RPC process, to help decouple the linear growth of connections from the associated threads, and enhance scalability. Once we have this in place, it will be easier to adopt a stream-based connection for participants.
De-risk complexity at every turn
Canva Live is one of only two streaming services at Canva, meaning we didn't have many established patterns to guide us. Since we're working with a lot of new systems and libraries such as PubSub(Flux) for reactive streams, Lettuce and Redis, we wanted to make sure that we could launch to staging quickly, and validate the architecture and as a foundation to the final production version.
Firstly we poll Redis at one second intervals to reduce complexity. Secondly, we decided to use request/response services for the participant side of Canva Live. Then, we implemented the data access layer using an in-memory database.
Although the in-memory database implementation limited us to a single instance deployment, it allowed us to quickly validate our assumptions and ensure that the entire streaming architecture works as intended.
To give more context on our technology stack, our in-memory database replicates the Redis streams with a Java Deque implementation, and the Redis SortedSet is a HashMap in Java. Once the redis implementation of the data access layer was ready, we swapped the in-memory version with the Redis version.
All the above ways of de-risking complexity seems to be contrary advice to 'Building for scale from day 1'. It is worth noting that 'Building for scale from day 1' does not mean trying to achieve perfection. The goal is to avoid making technical decisions that will significantly hamper our ability to scale to millions of users.
Some of these ideas were borrowed from other Canva teams that had more experience in building similar systems. Leveraging the knowledge of other exceptional engineers was essential to de-risking the complexity of this system.
Move towards end-to-end reactive processing
We use Project Reactor (https://projectreactor.io/(opens in a new tab or window)) to implement Reactive Streams on the RPC side. On the browser side, we use RxJs to receive events, and React, to paint the different parts of the UI in an asynchronous manner.
At the beginning of our first Canva Live implementation, only our service API was using the Flux and FluxSink to flush events to the browser. However, building an entirely reactive system does supply the benefits of increased resilience, responsiveness and scalability. Due to this, we are making inner-layers reactive, all the way to the database. Our usage of lettuce, which uses the same Flux/Mono API as Reactor is ideal, as it helps our cause in writing an end-to-end reactive system.
Conclusion
As of now, Canva Live is enabled to all users, and we're seeing an incredible number of sessions lighting-up our backend systems.
Building distributed systems that operate at scale is complex. Adding streaming support takes that complexity to a whole new level. Having said that, we truly believe we have built a streaming NRT system that scales with demands of our users, and will help foster an interactive, seamless presentation experience.
Please take a moment to try out Canva Live, and let us know your thoughts.
Appendix
Building the backend infrastructure for Canva Live is a result of the joint effort of Anthony Kong(opens in a new tab or window), James Burns(opens in a new tab or window), myself(opens in a new tab or window) and innumerable other engineers that have been extremely selfless in reviewing our designs and guiding us along the way. The gateway piece of this puzzle is built and maintained by our awesome Gateway Engineering team.