Machine Learning
How to improve search without looking at queries or results
How we improved Canva’s private design search while respecting the privacy of our community.
In October 2024, Canva celebrated the milestone of 200M monthly active users (MAUs). Our customers have over 30 billion designs on Canva and create almost 300 new designs every second. With this growth rate, the ability for Canva Community members to effectively search for and find their designs, as well as those shared to them by team members, is becoming an increasingly challenging and essential problem to solve.
In fields of public search, such as web or product search, the standard approach for evaluating a search engine offline is to use a dataset of sampled user queries and a fixed set of items in the search index. Expert human judges then label the dataset and rate the relevance of each query to every item in the dataset. Recall and precision metrics can then be calculated by comparing the labels to the results returned by the search engine.
Privacy is incredibly important to Canva. One of our core values is to “Be a Good Human” which applies to everything we do, including handling our community’s information and creations. This means viewing personal Canva designs is strictly off limits, removing the possibility of labeling real user data to act as our evaluation dataset for private design search. Without this data, how do we evaluate changes to the search pipeline and decide which ones are worth shipping to users? Generative AI provided the answer, allowing us to create realistic but entirely synthetic content and queries with zero privacy concerns.
This blog post outlines how we built our dataset, the tools we used for evaluation, and the issues we faced along the way.
Original state
Previously, the only option available to engineers was very limited offline testing. The usual approach was for an engineer to run a few known bad queries in their own Canva accounts before and after implementing their code changes. For example, an engineer working on improving spell correct might test the misspelled query “desgin” and see no results returned before implementing their improvements, while several documents containing the word “design” are returned afterwards.
Anything that passed this short manual round of testing then moved onto the final stage of online testing. This involves using Canva’s experiment framework to run an A/B experiment to compare search success rates for users exposed to these changes with those users experiencing standard search behavior.
This approach had several issues:
- The method of offline testing had limited statistical power to detect poorly performing changes. Observed improvements in the small number of queries tested was not necessarily indicative of performance across a wide range of different query behavior.
- By progressing changes quickly to online experimentation, we risked exposing users enrolled in experiments to detrimental search behavior, in cases when poor performance was not picked up by offline testing.
- Each online experiment requires a minimum number of user interactions to reach statistical significance, and can take several days to weeks. This limited the number of experiments we could run concurrently and reduced the speed at which we could test different ideas.
Ideal state
For more efficient experimentation, we needed a custom dataset and evaluation pipeline to allow engineers to objectively evaluate changes offline before progressing them to online experimentation. There were a few aspects that we deemed essential when building this pipeline:
- Reproducible results: Results needed to be reproducible, regardless of the user or state in which we ran an evaluation.
- Fast iteration: Engineers needed to be able to rapidly test changes, without having to wait several days for their code changes to reach production.
- Realistic production results: Results needed to be an exact reflection of the behavior we expect in production.
- Non-blocking: Engineers across the team needed to be able to experiment on their own code changes in parallel, without blocking other engineers.
Generating realistic private search datasets
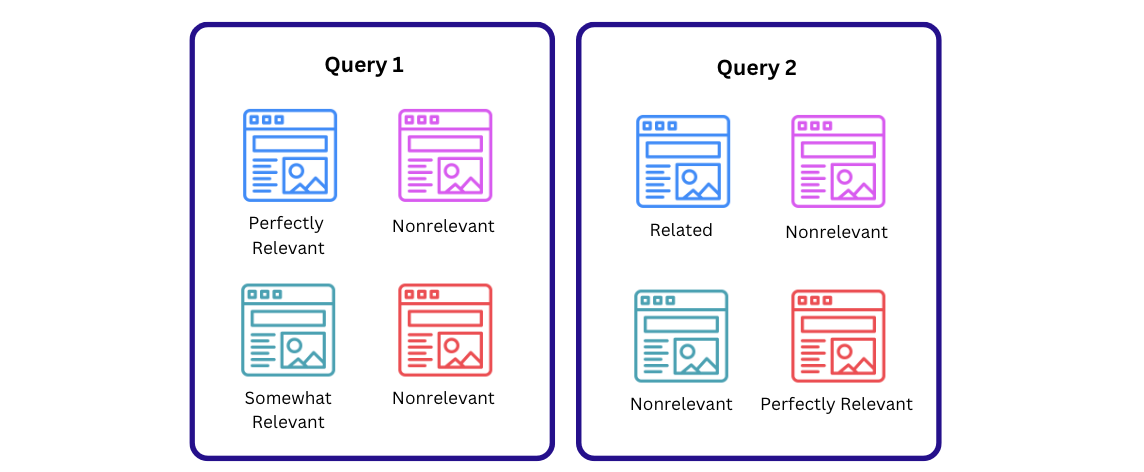
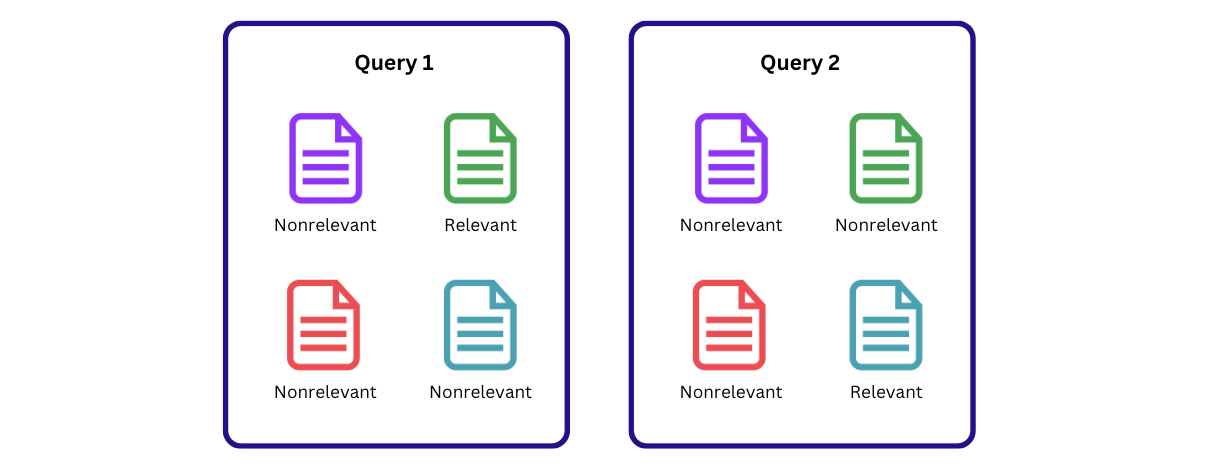
The first step to achieving these goals was to build a labeled evaluation dataset. In the public search domain, where there are often multiple items that could be relevant to a single query, labels consist of a relevance value for each query and item pair. These can be binary or numerical values, representing each item’s relevance level to the query (see Figure 1). In our private search domain, we were specifically focussed on evaluating the task of re-finding. That is, when a user is trying to find a design they either created or have viewed before. For each query, our labeled dataset therefore consists of a relevant label for the single design the user is trying to re-find with the query and nonrelevant labels for all other designs in the corpus.
Each test case then had the following components:
- A test query.
- A relevant design representing the design the user is searching for with their query.
- Optionally, additional designs that could potentially be retrieved by the search query. This was only required for test cases measuring precision, not recall.
The large-scale availability of large language models (LLMs) means that large corpora of realistic text documents can be generated efficiently and scalably. Previous(opens in a new tab or window) work(opens in a new tab or window) has also shown that information retrieval datasets with queries generated by GPT-4 can produce evaluation results of similar quality to using traditional test collections with human generated queries.
Test cases to measure recall
To generate each test case in our dataset, we seeded GPT-4o with a realistic topic for a design. We also specified a design type, such as document, presentation, or Instagram post, which was sampled from the distribution of real Canva design types, and prompted GPT-4o to brainstorm some titles for this design. After selecting one of the titles, we used a second prompt to generate the corresponding text content for the design.
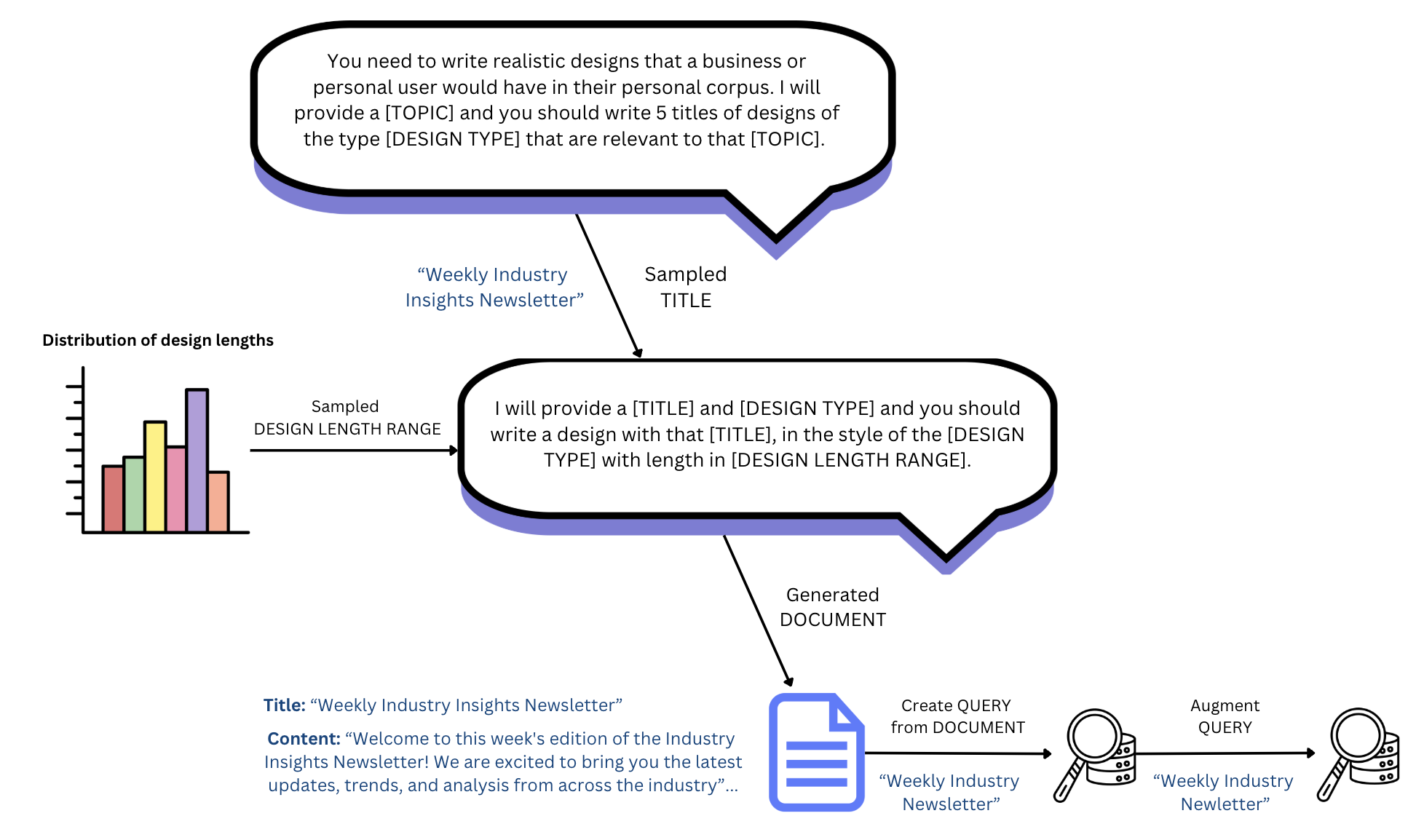
Privacy constraints restrict us from viewing user-created content on Canva. However, we can calculate aggregate statistics about the distributions of the length of designs in a privacy-preserving manner, allowing us to create designs with a realistic number of characters. This requirement is important because the longer the text content, the higher the likelihood of a match between the query and content, increasing the chance of a design being returned in search results.
Queries were then generated from these relevant designs using a combination of programmatic techniques and rewriting by GPT-4o. For example, an easy query might be created by sampling one or more words from the design’s title or content. These queries were then often modified in specific ways to increase the query difficulty level. Some examples include:
- Misspelling one or more words.
- Replacing words with synonyms.
- Rewording the query using GPT-4o.
The output of this pipeline is a single query, paired with the relevant design that it’s targeting (See Figure 3). This is a useful test case for measuring recall.
Test cases to measure precision
To create test cases to evaluate precision, we require both relevant and nonrelevant designs in the search index for each test query. This allows us to observe the rank of the relevant design relative to other designs returned by search. To create these additional designs, we used a combination of the query and content of the relevant design.
In the first example in Figure 4, GPT-4o generated designs containing some, but not all, of the words from the query. This approach ensures that the nonrelevant designs have a lower level of text match to the query compared to the relevant design. In the second example, we create various modified versions of the relevant design, such as templates or drafts of the document. Apart from altering the text content, we can also modify other design attributes to diminish their expected retrieval rank, for example, by making the nonrelevant designs older and less recently accessed.
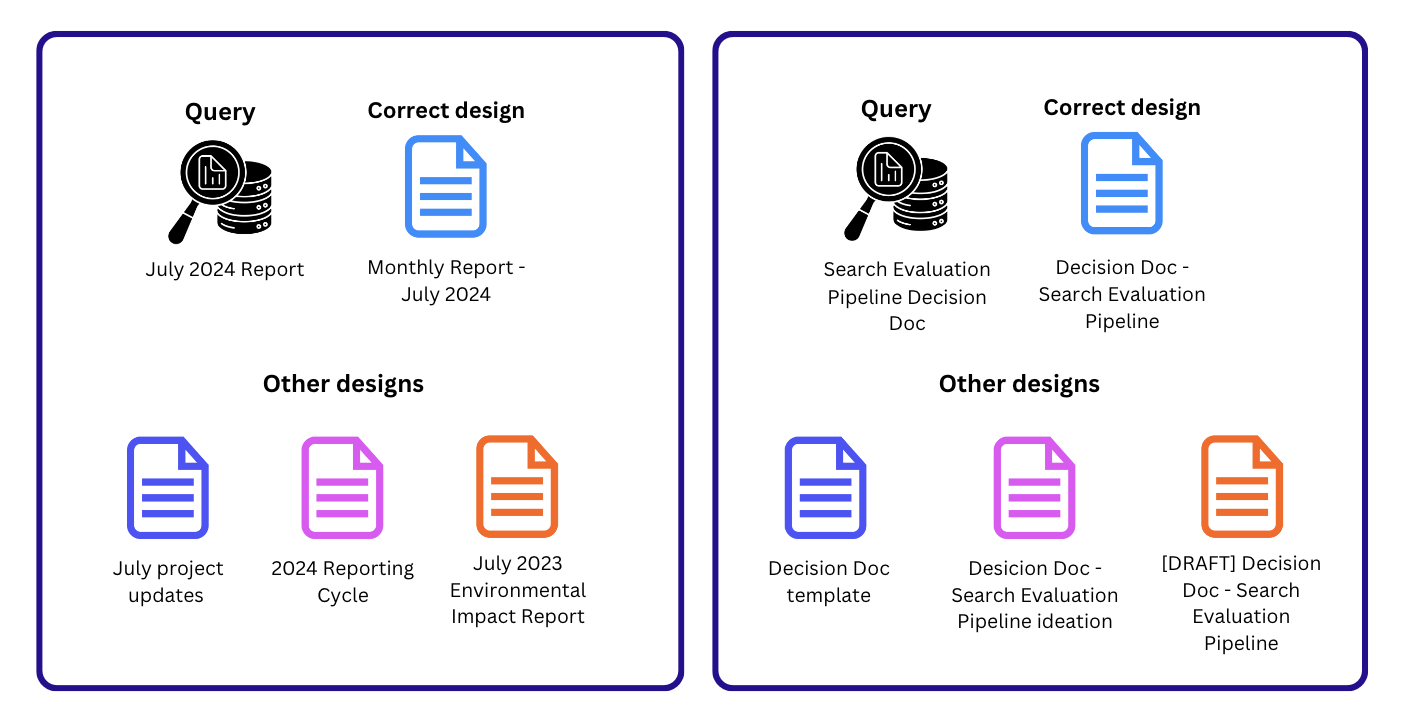
We also introduced other generic designs into the corpus for each precision-related test case. These designs are unrelated to the query and allow us to create test cases with various different realistic corpus sizes.
Issues encountered using LLMs
Leveraging LLMs to develop a static evaluation dataset that can be shared among engineers allows us to capitalize on one of their greatest strengths: scalable text generation. At the same time, we eliminated the impact of LLM issues such as latency and randomness because once we create the dataset, we can use it repeatedly to produce consistent, deterministic evaluation results in a matter of minutes.
However, we still encountered several issues with GPT-4o following instructions when generating our dataset, including:
-
Refusal to create designs with very long titles. When instructed to create titles containing 12-15 words, some examples of the titles returned included:
- Exploring the Latest Advancements in Screen Technology and Applications (9 words).
- Best Practices for Teachers: Presentation Tips for Meet the Teacher (10 words)
This, however, made us re-think our choice of title lengths, as the LLM’s refusal to create titles of this length may indicate that they are infrequently seen in real documents.
-
Repetitions and hallucinations when instructed to create multiple realistic misspellings for a word. For example, when instructed to misspell the word “Calendar” differently 3 times and provide reasoning, it returned the following.

-
Issues adhering to strict instructions for the nonrelevant design titles.

Frequently the returned titles from this prompt contained the “title string” or didn’t contain all of the words in the title words list.
 Figure 5: Examples of design titles generated using the above prompt
Figure 5: Examples of design titles generated using the above prompt
Running the evaluation
Once we had our synthetic dataset, we needed a way to run this data through our search pipeline and output evaluation metrics. We explored several possible methods to achieve this.
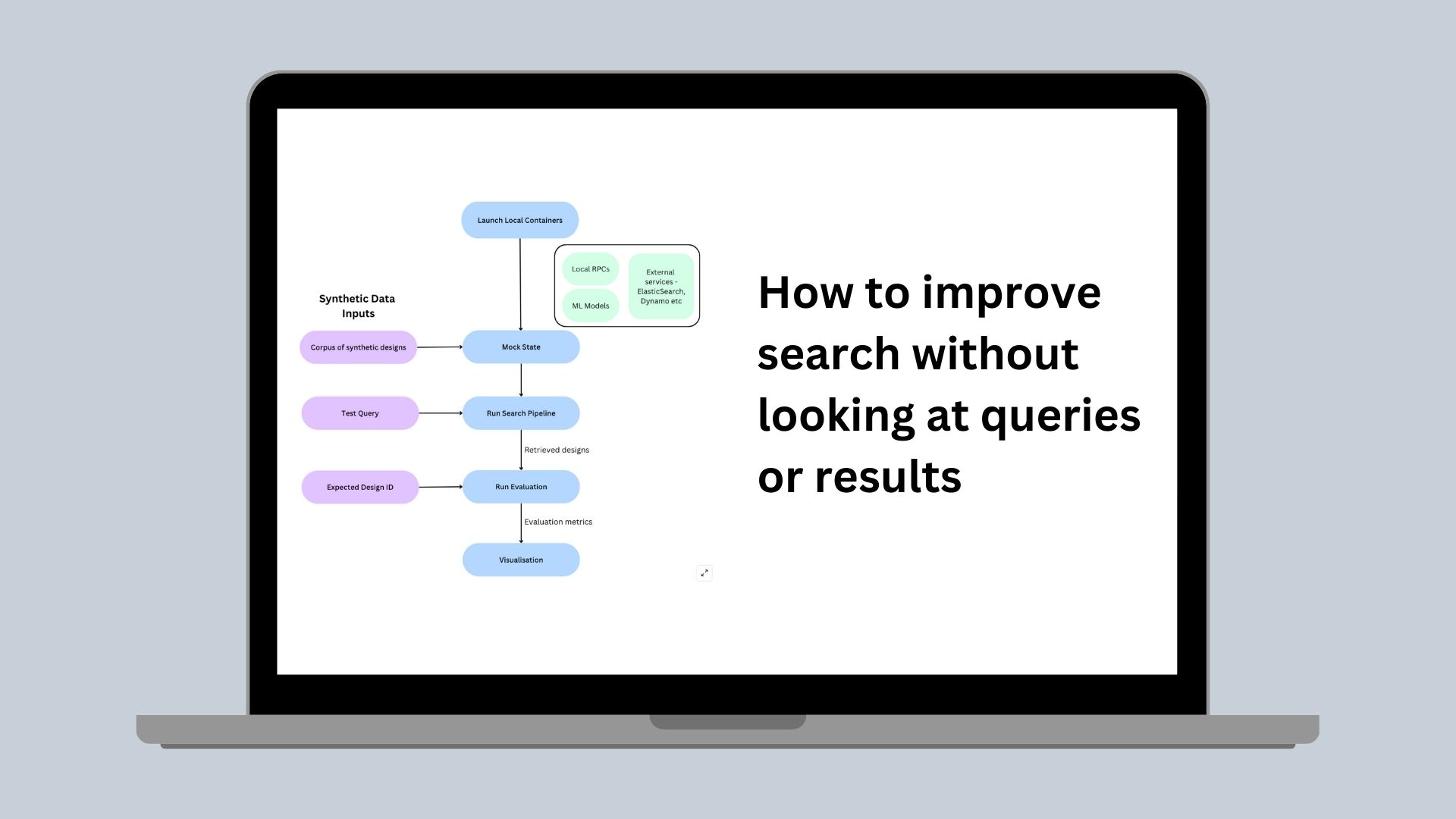
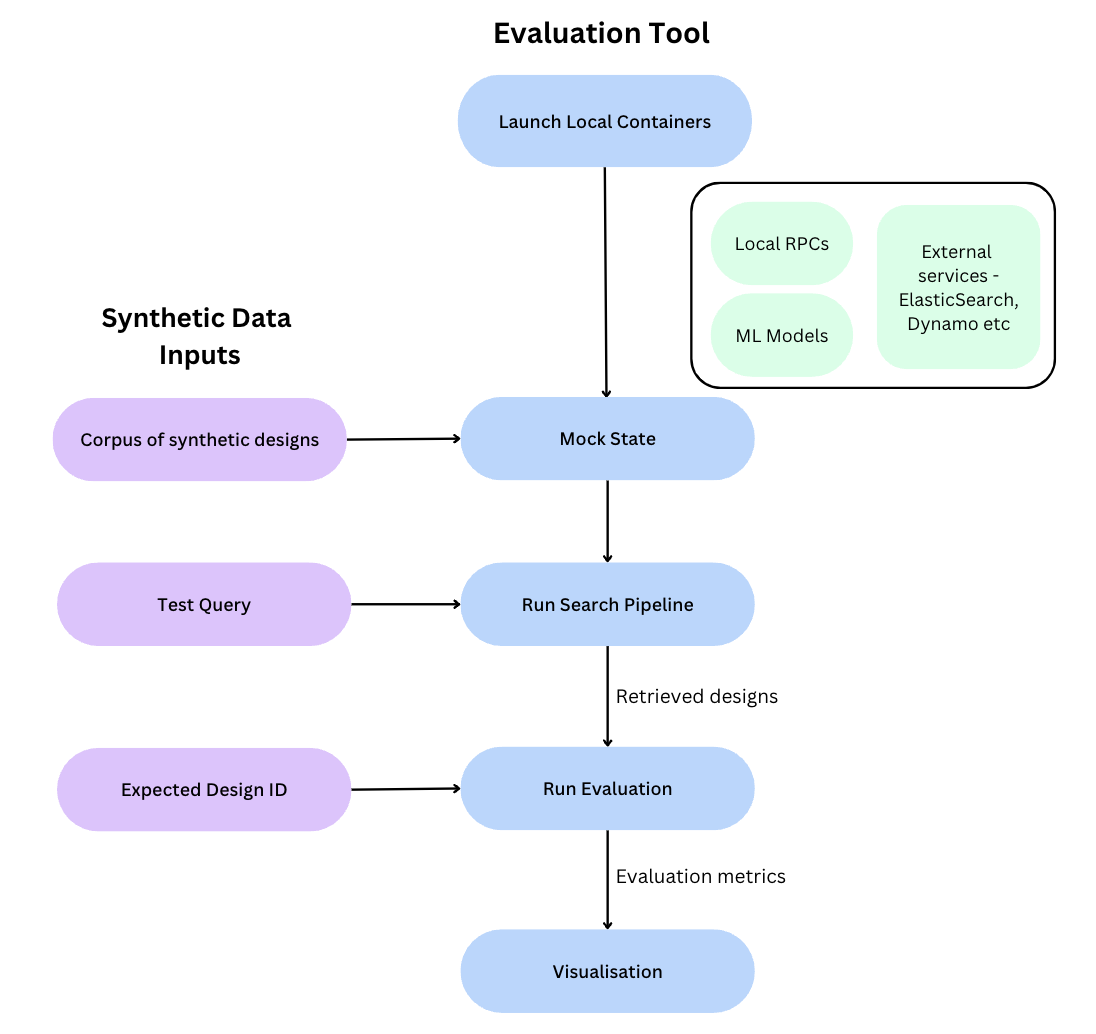
The method we settled on was to run all the components required for the search pipeline locally using Testcontainers(opens in a new tab or window). Canva already has great Testcontainer support for our service-orientated RPC architecture, which we use internally for running integration tests. We capitalized on this existing functionality, building a pipeline in which we combine externally supported containers for components such as ElasticSearch, with our own internal Testcontainers, run with an exact replica of our production configurations. We also run the ML models that support our search pipeline locally, allowing engineers to experiment with different model variants.
For each test case, we create the required state containing all of the designs for that test case. Instead of generating actual Canva designs, we simplify the process by extracting and populating only the design data required by our search index. We then run the local search pipeline on this state with the test query and pass the results to our evaluation module to calculate recall and precision metrics.
The following diagram shows the flow of data through the evaluation tool.
Visualizing the results
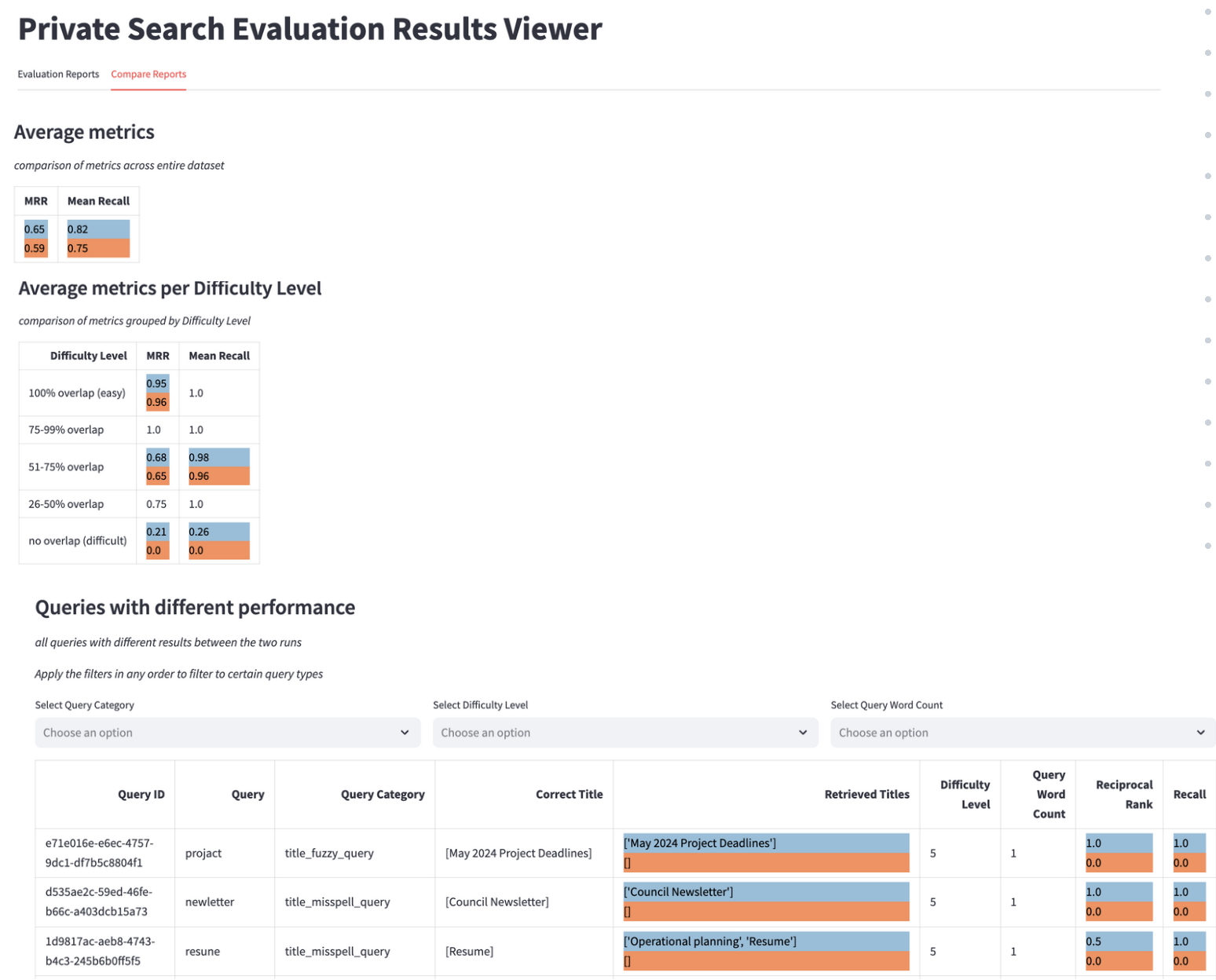
The final step was to allow engineers to effectively visualize, understand, and compare their evaluation results. To do this, we built our own custom visualization tool using Streamlit(opens in a new tab or window). This tool allows for comparison of the aggregated recall and precision metrics for different configurations side by side, as well as segmenting the performance by different query types and difficulty levels. We also display the output of individual queries to allow for precise debugging of different use cases. This tool launches immediately after the evaluation is complete, allowing engineers to quickly make informed decisions about the performance of their changes and rapidly iterate, independently of the work of any other engineers on the search pipeline.
Impact and future plans
So, how close did we get to our ideal state? Our evaluation dataset and tooling produces completely reproducible evaluation results within minutes, with engineers able to independently and objectively evaluate their code changes locally and have confidence that the results are a true reflection of production behavior. All of this is done in a completely privacy-preserving manner, without viewing a single customer’s designs or queries.
Some highlights include:
- Rapid iteration: Our offline evaluation tool outputs results on our more than 1000 test cases in less than 10 minutes. That means we can perform more than 300 offline evaluations in the same 2-3 day period that it would take for code to reach production and complete a single online interleaving(opens in a new tab or window) experiment.
- Positive correlation between offline results and online experimentation: Offline evaluation is only useful if it allows us to eliminate poorly performing ideas while passing through those likely to be successful to the next stage of online experimentation. While developing our evaluation system, we ran several experiments to ensure that offline and online results were in sync. These showed robust alignment for changes with both positive and negative performance on our offline metrics.
- Local debugging functionality: Our evaluation tool facilitates local debugging of the search pipeline, allowing a user to observe the flow of a test case through each pipeline component. This is a far more efficient process than previous debugging methods, which relied on production logs to troubleshoot search behavior in a live production environment.
This system is only the beginning of synthetic data evaluation. We’re continuing to expand our datasets with more realistic features, such as sophisticated collaboration graphs, as well as improving our tooling to allow engineers to efficiently self-serve their own specific synthetic data needs. Aided by generative AI, we plan to continue to harness the extensive opportunities synthetic data provides to help make Canva’s search tools the best possible experience for our community.
Acknowledgements
Huge thanks to Peter Bailey(opens in a new tab or window) for the endless guidance and advice he provided throughout the life of this project, as well as for thoroughly reviewing this article. Thanks to Nidhinesh Nand(opens in a new tab or window) for his work on the backend to bring this tool to life, and to all of the Private Search Quality team for their feedback that shaped the direction of our tooling and datasets. Thanks also to Will Radford(opens in a new tab or window), Sheng An Zhang(opens in a new tab or window), Karl Hornlund(opens in a new tab or window), Paul Tune(opens in a new tab or window) and Grant Noble(opens in a new tab or window) for reviewing this article.