Data Science
Subscription analytics at scale
Evolving Canva's subscription data architecture to enable data-driven decision making.
Canva Pro(opens in a new tab or window) is our flagship subscription product, first launched in 2015. It is a Software-as-a-Service (SaaS) subscription, with the option of a monthly or yearly subscription.
Canva users who subscribe to Canva Pro get a suite of features, such as a brand kit(opens in a new tab or window), background remover tool(opens in a new tab or window), and magic resizing(opens in a new tab or window) to change the size of their designs, thus making users more productive. Moreover, they now have access to more than 100 million ingredients, such as images and animations, to use in their designs. These features not only allow subscribers to create more beautiful designs, they also help with improving overall productivity with time saving features, such as scheduling Instagram Posts through our content planner(opens in a new tab or window) feature.

The scale of our subscriptions, however, poses a challenge from a data perspective. As of the writing of this post, we have more than 3 million subscribers(opens in a new tab or window), and many more users trialling the Canva Pro product. All these are important data points that enable the Product and Growth teams to have a full picture of the performance and impact of product launches, feature improvements and experiments, and also to further optimise the overall Canva user experience.
In this blog post, we'll discuss how the Canva Data team built the data warehouse infrastructure for subscription, unified key business metrics computation, and leveraged subscription data to model churn. We also briefly cover an application of machine learning to subscriptions.
Evolution of Subscription Analytics at Canva
Before going any further, here's how Canva Pro subscriptions work.
Canva Pro has options for a monthly or yearly subscription. The yearly subscription offer is cheaper on a month-by-month basis so as to provide a discount to long-term subscribers. Prices of these subscription plans are localized to the subscriber's country with localized options for payments.
Canva Pro subscriptions are preceded by a trial period, where a Canva Free user can try the Pro product for a limited amount of time. Trials are started when a Canva Free user clicks on a Call-to-Action (CTA), as shown in the following example.
A trial period lasts 14 days for mobile subscriptions and 30 days for desktop subscriptions. During a trial, users can enjoy all the benefits of Canva Pro, complete with an onboarding flow to help them get acquainted with our premium features. At the end of the trial period, users have the option to upgrade to Canva Pro and enjoy all the additional features, or go back to using Canva on a free basis. A subscription continues, whereupon subscription renewals happen every month or year depending on the option chosen, or terminates if the subscription is cancelled.
How we improved our data pipeline
Previously, Canva launched the first version of its subscription service, the subscriptions service 1.0, which was built on Stripe's subscription service. All the SaaS metrics such as annual recurring revenue (ARR), conversion, churn, reactivation, and our unit economics were hosted and tracked by third parties. We used Profitwell(opens in a new tab or window) to track our aforementioned key metrics and analyze churn. This system performed well when Canva was relatively small.
As Canva scaled rapidly, however, we needed to design and build a better data stack.
For instance, analyzing churn with Profitwell was limited because we needed to do a breakdown on a per country basis, differentiate between monthly and yearly plans, and drill down into other segments, such as growth in the Latin America region. At the time, subscriber Lifetime Value (LTV) was computed within Profitwell. Unfortunately, with the underlying equation for LTV being proprietary, this was an issue for us because we needed to be clear what LTV meant in our context.
Also, our subscription model has some differences compared to a standard subscription model. Consequently, Profitwell's metrics no longer provided the right metrics about our subscribers.
Given these and other challenges, we needed a stack that meets the following criteria:
- Scalability: Subscription data needs to be transformed in such a way that model tables and reports built on top of it can easily scale as Canva introduces additional plans, pricing, and payment gateways.
- Flexibility: Data has to be granular enough to be segmented in a variety of dimensions, and to define key metrics that meet our ever evolving business needs.
- Trustworthy: Data quality is crucial, especially for the subscription service, because insights and reports generated from the data enable the Product and Growth teams' decision making. Our revenue and churn data are also critical for management and for investors to monitor the overall health of the business.
- Accessibility: Data is not useful unless it is accessible to Canva's internal teams including Product, Growth, Finance, Design, and Engineering.
While a growing subscriber base is a good problem to have, something had to be done, and done quickly.
We started with a basic roadmap as a long-term vision of how we wanted to evolve our subscription analytics. This helped inform the nature of our future tools and stack. It was very clear that we were still in the Data Analytics stage, so our immediate goal is to improve our subscription modelling and the analytics surrounding that. We had our work cut out for us.
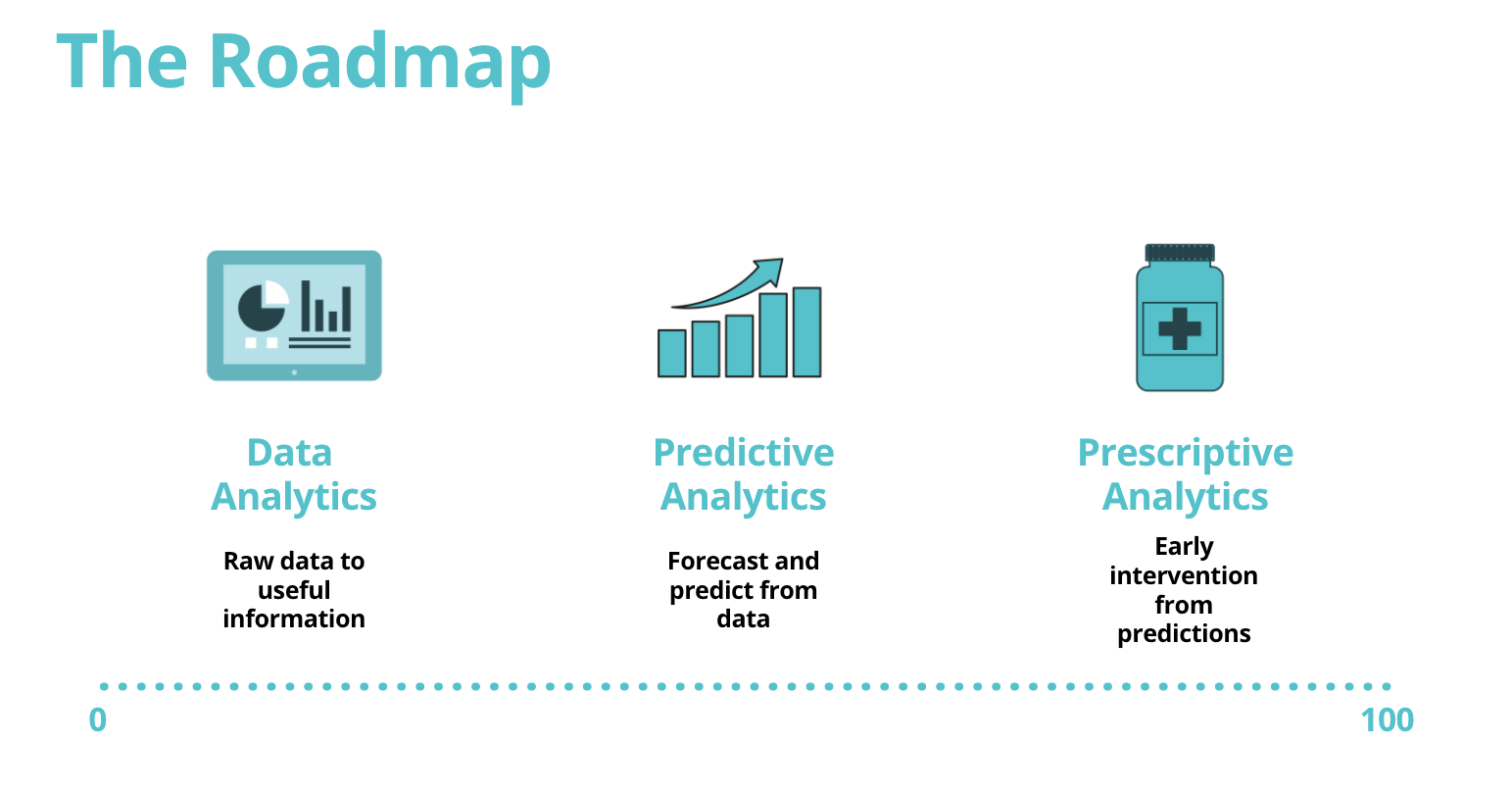
Our improvements in analytics came because of two major factors: a better schema for subscriptions, and a change in our data warehouse infrastructure and analytics tooling. Note that the latter came as part of an organization-wide change.
To address each of these factors, the Data team redesigned the schema of Canva's core subscription tables. By linking and aggregating information from multiple sources, including subscription, billing, profile, attribution, and events, we can now consolidate metadata on millions of subscribers into a single source, providing insights on conversion, renewal, and cancellation. Prior to this, getting this level of information often took an analyst half a day to query!
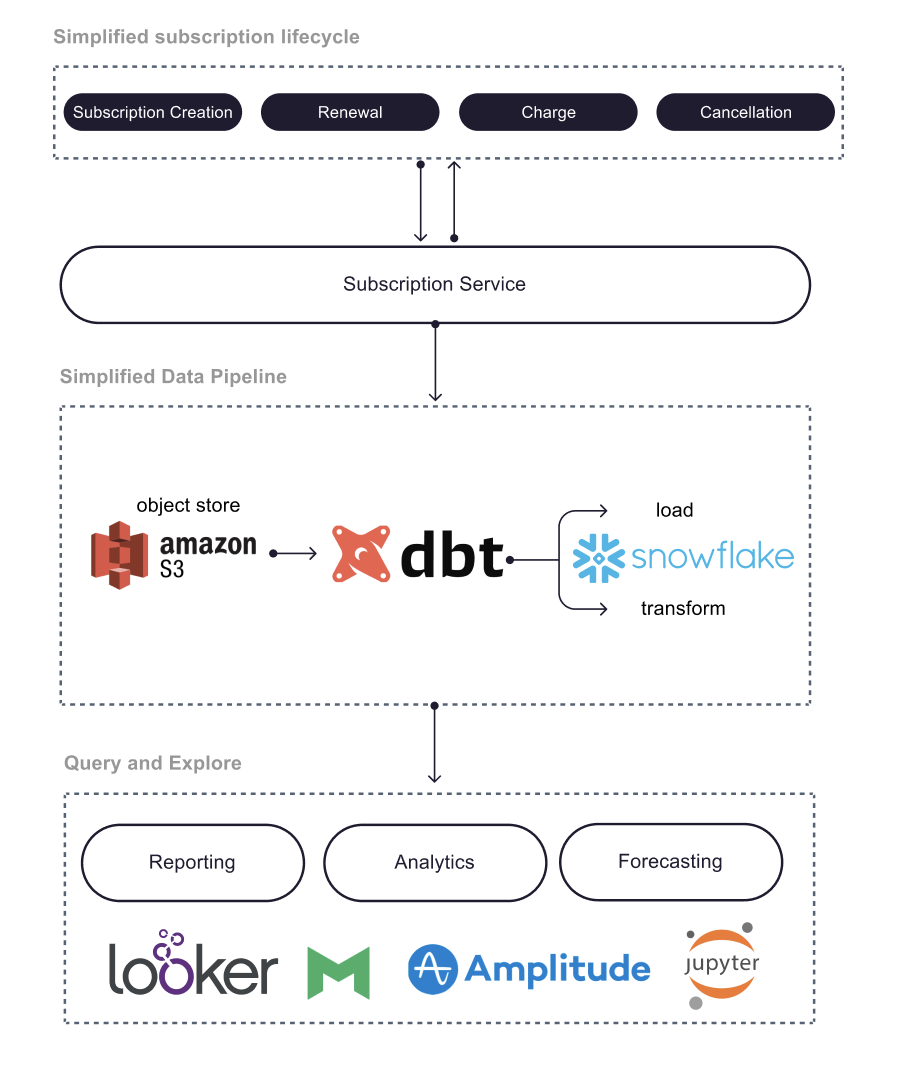
Moreover, we also redesigned our data pipeline for subscriptions. The following diagram summarizes our current data pipeline.
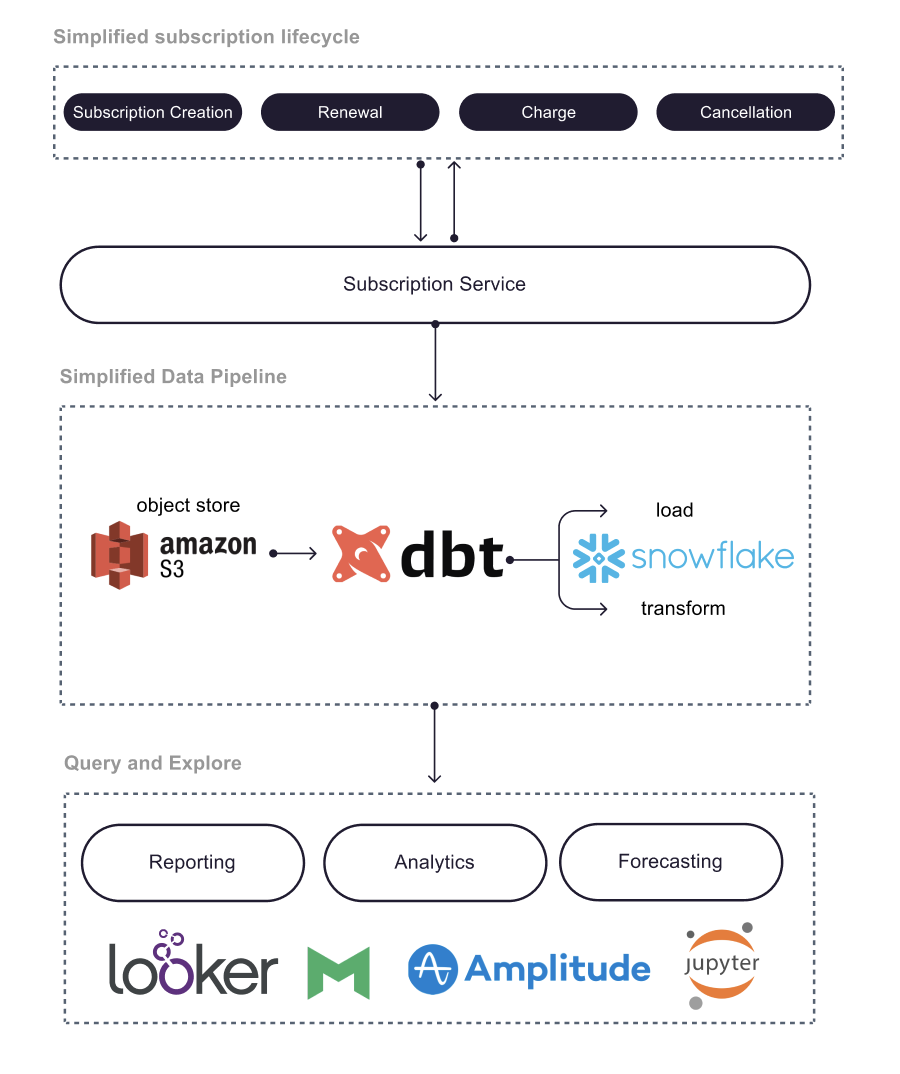
We had to migrate our subscriptions tables and associated tables, such as payment charges, to Snowflake(opens in a new tab or window), basically translating tables written in Presto(opens in a new tab or window) and Hive(opens in a new tab or window) to the Snowflake SQL dialect.
The data build tool (dbt)(opens in a new tab or window), in particular, was a very useful tool that allowed us to template and share common user defined functions. We were also able to, for the first time, test the quality of our tables via schema and data tests available in dbt. We also spent additional time improving the query efficiency of these tables.
As a result, we improved our analytics on subscriptions, which allowed us to hit the criteria outlined above.
We can now measure churn on a more granular level, for example by cohort date, country, plan platform, and upgrade path. This provides greater insight into the nature of our subscribers, retention performance over time, and insights for Product and Growth for growth funnel improvements. The introduction of data visualisation tools, including Mode and Looker, allowed Product and Growth teams to also self-serve if they have data questions.
Aside from the benefits above, these changes allowed us to unlock many opportunities that redefined the data culture at Canva Pro Group (now part of Business and Education Supergroup), including:
- Unified headline metrics trial conversion rates in our experimentation framework cross company.
- Centralized reports and dashboards for anyone to access.
- Machine learning to predict subscriber retention from demographics and usage behaviors.
- Insights and analytics to inform and improve product onboarding and user retention by finding leading indicators of retention from subscriber behavior.
Now let's see how we can forecast churn because of these improvements.
Forecasting churn
Our improvements in the Data Analytics phase of our roadmap allowed us to make progress in the Predictive Analytics phase. One clear application is the forecasting of churn.
What is churn to us?
The term "churn" itself is a loaded word. We define it as a subscriber no longer wanting to subscribe to Canva Pro by cancelling their recurring payments. We need to break this down into two different categories of churn to figure out how to reduce churn.
Voluntary churn refers to a subscription being cancelled because of the subscriber actively cancelling their subscription. Involuntary or delinquent churn refers to a subscription being cancelled not because of the direct action of the subscriber in cancelling the subscription. This latter category of churn could be because of missed subscription payments causing an automated cancellation.
Here, we focus on voluntary churn on a per-subscriber basis. This is then linked to subscriber LTV to be used in various applications in finance and marketing.
You can visualise the churn cohorts through graphs in this link(opens in a new tab or window). Typically, the churn rates increase as the months progress in each cohort. Over time we want to see the churn rates in the tail decrease, which shows that our new product features and improvements are retaining subscribers for longer. It is also a good way to provide our product and growth managers with a snapshot of retention.
Modelling churn
Let's touch on a little more about modelling SaaS churn. For example, consider monthly subscriptions. If we look at a single subscriber, for each month, the subscriber either retains or churns. This is essentially equivalent to a coin toss, where every month for a single subscriber can be modelled by a Bernoulli trial.
We set X to be a random variable that denotes if a monthly subscriber churns at month t. Suppose we denote the probability of churn as p. Then,
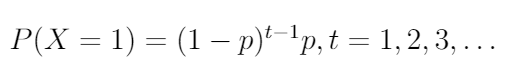
This is simply the geometric distribution(opens in a new tab or window). However, this model is naive because it assumes every subscriber has the same churn rate. As we know from our data, this assumption is false. Every subscriber has a different churn probability.
We instead use the Fader-Hardie model(opens in a new tab or window), which at its core, assumes every subscriber has a different churn probability, which can be described by a probability distribution, which is a Beta distribution(opens in a new tab or window). We defer details of this model to the paper, which has demonstrated its advantage over other churn forecast models, such as an exponential and quadratic fit.
There are two advantages to this model. One, it is interpretable, which allows us to figure out what is going on. Second, we found that the model adequately forecasted churn well with just two data points (that is, two months of retention), although naturally more data points would lead to better forecasts. This is a great boon to us because it makes it easy to figure out the LTV of a particular cohort of subscribers. Over time, as we get more data points from the actual churn rates for the cohorts, our forecasts become more accurate.
We had to modify the model slightly to fit our needs. In particular, as Canva subscribers come from all over the world and design on a variety of devices, for reporting purposes, we had to forecast churn on a per country and per platform basis. We also adapted the model to monthly and yearly subscriptions, which have very different churn rates. Churn typically happens on a yearly basis for yearly subscriptions.
Role of Machine Learning
Machine learning is being applied to help map out the conversion funnel at Canva. The deployment of some of these applications are relatively nascent but growing.
One application is to predict users that are likely to convert to a paying subscriber after the trial period. We have a trial-to-paid predictor, operational since September last year, which provides insights and ideas on intervention of trialling users who are unsure about converting to a subscription.
Machine learning models have a reputation of being black boxes. That is, their inner workings are opaque, making it hard to explain how a prediction is made. Since we often get requests from product managers and marketers about the segments of users and their behavior that led them to becoming a subscriber, explainability is a key requirement here.
At present, our models are based on logistic regression, but we are experimenting with tree-based models, such as XGBoost(opens in a new tab or window). Based on our experience, however, a lot of our gains came from improved quality of the data sources, so we continue to invest in data cleaning and data quality testing.
Lessons
We learned a few lessons along the way.
- Data gathering from multiple sources is challenging. A typical challenge for anyone in the data analytics space is the philosophy of separation of concerns. Separation of concerns is the software engineering principle of ensuring that a service does only one thing, and one thing well. On the one hand, it ensures Canva is reliable and robust to failure. On the other hand, it makes it very difficult to collect data from multiple production services to provide the best picture of a subscriber (and even a typical user) at Canva. We found that having a good and established process between the owners of a service and analytics helps with reliable and timely collection of data.
- Having a solid data infrastructure is important before good data analytics can get off the ground. Everyone wants to get the answers to their queries faster, but this would be nearly impossible without a timely and reliable process in data collection, data ingestion, and data quality checks. Moreover, the underlying infrastructure has to perform fast, reliably and efficiently at scale.
- When it comes to using data effectively, it's important to not put the cart before the horse. It's tempting to apply machine learning before investing in proper data infrastructure and analytics. However, machine learning is only as good as the data that goes into it. By investing in improving our data to a level where we have exploited all the easy insights from the data, we are now in a position to pool together large sets of varied (that is, heterogeneous) data to provide insights not immediately obvious to an analyst using machine learning.
Acknowledgements
This work would not be possible without the support across our Data specialties and our entire organization. Special kudos to Steven Maikim, who was with us in this journey from the very beginning ❤️.
Inspired by this post? Passionate about data? Join us(opens in a new tab or window)!